注意:
-
#define int long long&&signed main(){},但这样宏定义可能导致TLE/MLE或
typedef long long ll
[toc]
常用STL
algorithm
#include<algorithm>
1 | //algorithm 在STL中的应用主要是: sort() swap() reverse() find() |
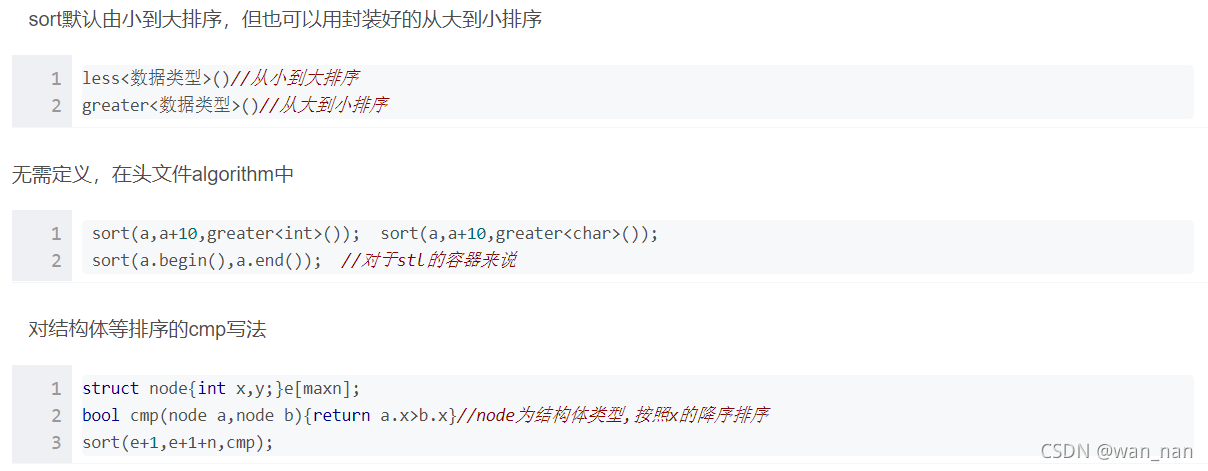
sort()
binary_search()

unique()
“删除”序列中所有相邻的重复元素(只保留一个)
此处的删除,并不是真的删除,而是指重复元素的位置被不重复的元素给占领了
由于它”删除”的是相邻的重复元素,所以在使用unique函数之前,一般都会将目标序列进行排序
unique函数的去重过程实际上就是不停的把后面不重复的元素移到前面来,也可以说是用不重复的元素占领重复元素的位置
1 |
|
find()
该函数会返回一个输入迭代器,当 find() 函数查找成功时,其指向的是在 [first, last) 区域内查找到的第一个目标元素;如果查找失败,则该迭代器的指向和 last 相同
值得一提的是,find() 函数的底层实现,其实就是用==运算符将 val 和 [first, last) 区域内的元素逐个进行比对。这也就意味着,[first, last) 区域内的元素必须支持==运算符
1 | string = "hello"; |
next_permutation()
next_permutation(num,num+n)函数是对数组num中的前n个元素进行全排列,同时并改变num数组的值
1 |
|
fill()
fill函数可以为数组或者vector中的每个元素赋以相同的值,通常用于初始化
与memset()比较,memset()一般用于整个初始化:void *memset(void *s, int ch, size_t n);
1 | //fill()给多维数组赋值 |
min_element() & max_element()
返回容器[begin, end)段中最小/大元素所在的第一个迭代器
1 |
|
lower_bound() & upper_bound()
lower_bound(first,last,val):first和last中的前闭后开区间进行二分查找,返回【大于或等于】val的iterator位置。如果所有元素都小于val,则返回last的位置
upper_bound(first,last,val):返回的在前闭后开区间查找的关键字的上界,返回【大于】val的iterator位置
math
#include<cmath> // #include<math.h>
使用时需要注意:输入参数绝大多数要求double双浮点类型
1 | double log (double); //以e为底的对数 |
vector
#include<vector>
vector构造方式:
1 | // 1、无参构造(默认构造) |
1 | push_back(); //在最后添加一个元素,参数为要添加的值 |
insert()
三种用法:
1.在指定位置loc前插入值为val的元素,返回指向这个元素的迭代器
2.在指定位置loc前插入num个值为val的元素
3.在指定位置loc前插入区间[start, end)的所有元素 ,返回元素的大小个数
a.insert(a.begin(),b,begin(),b.end());//在a的前面插入b
1 |
|
erase()
两个函数原型:
iterator erase(iterator position);
iterator erase(iterator first, iterator last); // 返回指向下一个元素的迭代器
1 | for (auto p1 = v1.begin(); p1 != v1.end();)//auto p1 = v1.begin() |
string
#include<string>
1 | data(); // 返回指向自己的第一个字符的const char*指针,指向的内存最后以空字符结尾 |
data()
append()
常用函数原型:
1 | basic_string &append( const basic_string &str ); |
append() 函数可以完成以下工作:
在字符串的末尾添加str
在字符串的末尾添加str的子串,子串以index索引开始,长度为len
在字符串的末尾添加str中的num个字符
在字符串的末尾添加num个字符ch
在字符串的末尾添加以迭代器start和end表示的字符序列
insert()
大概与vector的insert()类似
find()
1 | string str1, str2; |
查找字符
1 | //string.find()返回值 |

replace()
所有用法举例如下:
1 | str=str.replace(str.find("a"),2,"abc"); |
substr()
C++ 中substr()函数有三种用法,如下所示:
1 | string x=s.substr() //默认时的长度为从开始位置到尾 |
string->number
1 | std::string str; |
同样, 可以使用 stol(long), stof(float), stod(double) 等
number->string
string to_string (int val);参数可以是任意数字类型
set
#include<set>
1 | // set的特性是,所有元素都会根据元素的键值自动排序. |
1 | set<int> numSet; |
取取并集,交集,差集
1 | //set_union 取并集运算 |
map
#include<map>
map<string, int> mapStudent;
1 | begin() //返回指向map头部的迭代器 |
插入元素:
1 | // 定义一个map对象 |
简短的遍历方式
1 | for (auto & [key,val] : mapSum) |
查找元素:
1 | // find 返回迭代器指向当前查找元素的位置否则返回map::end()位置 |
删除与清空元素:
1 | //迭代器刪除 |
stack&queue
priority_queue
STL 在头文件中提供优先队列 priority_queue,在任意时间都能取出队列中的最大值,队列首部总是最大值
使用 push() 向优先队列中加入元素,其时间复杂度为O(logn)
使用 top() 获取优先队列中最大的元素(并不删除),其时间复杂度为O(1)
使用 pop() 删除优先队列中最大元素,其时间复杂度为O(logn)
使用 empty() 判断优先队列是否为空
也可以定义为优先最小值:
1 | priority_queue< T,vector<T>,greater<T> >q;//注意greater<int>后面要加空格,否则计算机会当右移运算符. |
greater 和 less是 std 实现的两个仿函数(就是使一个类的使用看上去像一个函数。其实现就是类中实现一个operator(),这个类就有了类似函数的行为,就是一个仿函数类了)
1 | //对于字符串按照字典序排序 |
deque
#include <deque>双端队列
1 | size() |
构造
1 | deque():创建一个空deque |
增加
1 | void push_front(const T& x):双端队列头部增加一个元素X |
删除
1 | dec.pop_back(); //尾部删除 |
list
构造函数:
list() 声明一个空列表;
list(n) 声明一个有n个元素的列表,每个元素都是由其默认构造函数T()构造出来的
list(n,val) 声明一个由n个元素的列表,每个元素都是由其复制构造函数T(val)得来的
list(n,val) 声明一个和上面一样的列表
list(first,last) 声明一个列表,其元素的初始值来源于由区间所指定的序列中的元素
begin()和end():通过调用list容器的成员函数begin()得到一个指向容器起始位置的iterator,可以调用list容器的 end() 函数来得到list末端下一位置,相当于:int a[n]中的第n+1个位置a[n],实际上是不存在的,不能访问,经常作为循环结束判断结束条件使用。
push_back() 和push_front():使用list的成员函数push_back和push_front插入一个元素到list中。其中push_back()从list的末端插入,而 push_front()实现的从list的头部插入。
empty():利用empty() 判断list是否为空。
resize(): 如果调用resize(n)将list的长度改为只容纳n个元素,超出的元素将被删除,如果需要扩展那么调用默认构造函数T()将元素加到list末端。如果调用resize(n,val),则扩展元素要调用构造函数T(val)函数进行元素构造,其余部分相同。
clear(): 清空list中的所有元素。
front()和back(): 通过front()可以获得list容器中的头部元素,通过back()可以获得list容器的最后一个元素。但是有一点要注意,就是list中元素是空的时候,这时候调用front()和back()会发生什么呢?实际上会发生不能正常读取数据的情况,但是这并不报错,那我们编程序时就要注意了,个人觉得在使用之前最好先调用empty()函数判断list是否为空。
pop_back和pop_front():通过删除最后一个元素,通过pop_front()删除第一个元素;序列必须不为空,如果当list为空的时候调用pop_back()和pop_front()会使程序崩掉。
assign():具体和vector中的操作类似,也是有两种情况,第一种是:l1.assign(n,val)将 l1中元素变为n个T(val)。第二种情况是:l1.assign(l2.begin(),l2.end())将l2中的从l2.begin()到l2.end()之间的数值赋值给l1。
swap():交换两个链表(两个重载),一个是l1.swap(l2); 另外一个是swap(l1,l2),都可能完成连个链表的交换。
reverse():通过reverse()完成list的逆置。
merge():合并两个链表并使之默认升序(也可改),l1.merge(l2,greater
看一下下面的程序:
1 |
|
运行结果:

insert():在指定位置插入一个或多个元素(三个重载):
l1.insert(l1.begin(),100); 在l1的开始位置插入100。
l1.insert(l1.begin(),2,200); 在l1的开始位置插入2个100。
l1.insert(l1.begin(),l2.begin(),l2.end());在l1的开始位置插入l2的从开始到结束的所有位置的元素。
erase():删除一个元素或一个区域的元素(两个重载)
l1.erase(l1.begin()); 将l1的第一个元素删除。
l1.erase(l1.begin(),l1.end()); 将l1的从begin()到end()之间的元素删除。
vector-list-deque

「ctype.h」
isalpha()用来判断一个字符是否为字母
isalnum()用来判断一个字符是否为数字或者字母,也就是说判断一个字符是否属于a到z/A到Z/0~9
islower()用来判断一个字符是否为小写字母,也就是是否属于a~z
isupper()用来判断一个字符是否为大写字母
isdigit() 用来检测一个字符是否是十进制数字。十进制数字包括:0 1 2 3 4 5 6 7 8 9
tolower()
将大写字母转换为小写字母,成功返回对应的小写字母,失败返回大写字母本身,返回值为int类型
toupper()
将小写字母转换为大写字母,成功返回对应的大写字母,失败返回小写字母本身,返回值为int类型
板子
random number
1 |
|
字符串filter分词
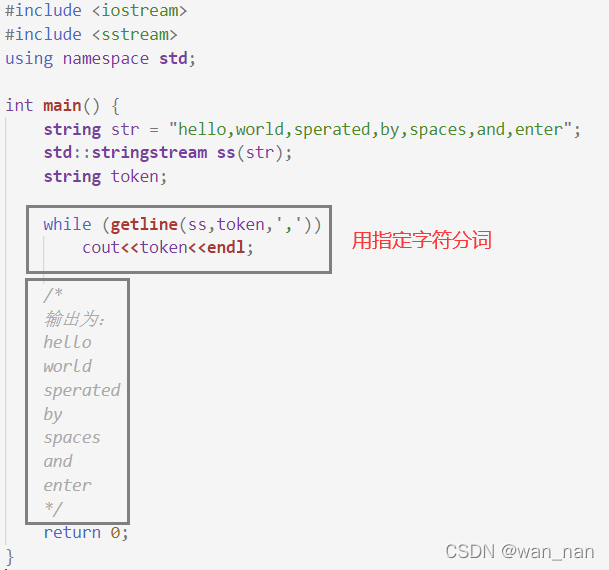
使用字符串流
stringstream,它将流与存储在内存中的string对象绑定起来上代码:
默认分词分隔符为:
空格、换行符\n、缩进符\t
用指定分隔符分词:
gcd(求x,y的最大公约数)
#include<algorithm>
__gcd(a,b)//a和b均为整型,注意是两个下划线__
1 |
|
基础算法
快速排序
1 | void quick_sort(int q[], int l, int r) |
归并排序
1 | void merge_sort(int q[], int l, int r) |
整数二分
1 | bool check(int x) {/* ... */} // 检查x是否满足某种性质 |
浮点数二分
1 | bool check(double x) {/* ... */} // 检查x是否满足某种性质 |
高精度加法
1 | // C = A + B, A >= 0, B >= 0 |
或者用__int128实现
1 |
|
高精度减法
1 | // C = A - B, 满足A >= B, A >= 0, B >= 0 |
高精度乘低精度
1 | // C = A * b, A >= 0, b >= 0 |
高精度除以低精度
1 | // A / b = C ... r, A >= 0, b > 0 |
数据结构
KMP
用例题说明
给定两个串P和S及他们的长度,求P在S中出现的所有下标(从0开始)

上题使用string.find()性能会比KMP差一点
使用find()
1 |
|
手撕KMP
1 |
|
搜索与图论
树与图的存储
树是一种特殊的图,与图的存储方式相同。
对于无向图中的边ab,存储两条有向边a->b, b->a。
因此我们可以只考虑有向图的存储。
(1) 邻接矩阵:g[a][b] 存储边a->b
(2) 邻接表:
1 | // 对于每个点k,开一个单链表,存储k所有可以走到的点。h[k]存储这个单链表的头结点 |
树与图的遍历
时间复杂度 O(n+m), n 表示点数,m 表示边数
DFS:
1 | int dfs(int u) |
BFS:
1 | queue<int> q; |
拓扑排序
1 | //时间复杂度 O(n+m), n 表示点数,m 表示边数 |
其他
cin cout优化
1 | ios::sync_with_stdio(false); |
tips
- 较大的数要用long long存
ans = (ans + MOD) % MOD;//避免负数取模
- 本文链接:https://wan-nan.github.io/2021/09/18/CSP%E8%AE%A4%E8%AF%81%E8%80%83%E8%AF%95%E6%9D%BF%E5%AD%90/
- 版权声明:本博客所有文章除特别声明外,均默认采用 许可协议。