本笔记为中国大学MOOC 华中科技大学计算机组成原理
第一章 概述
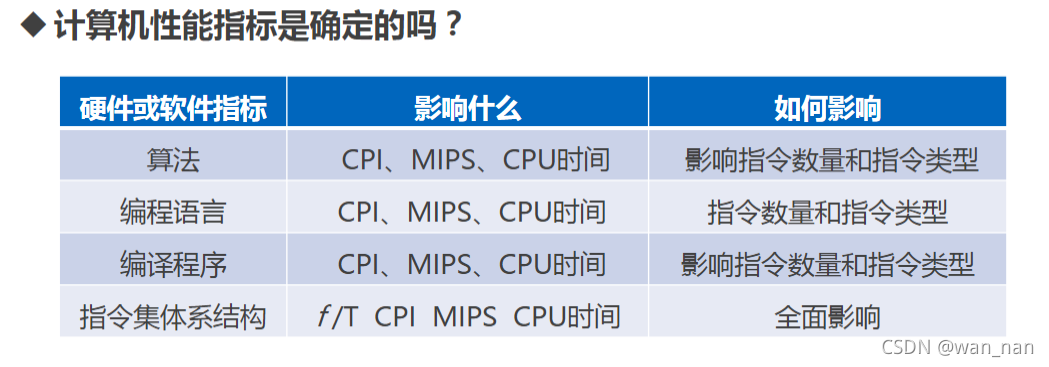
计算机系统性能评价
从非时间指标
非时间指标
机器字长:机器一次能处理的二进制位数(一般与内部寄存器的位数相等)
总线宽度:数据总线一次能并行传送的最大信息位数
主存容量:一台计算机主存所包含的存储单元总数
存储带宽:单位时间内与主存交换的二进制信息量,常用单位B/s(字节每秒)
时间指标
主频f/时钟周期T:主频=外频*倍频
CPI:(Clock Cycles Per Instruction)执行一条指令(平均)需要的时钟周期数,即T的个数
单条指令CPI,一段程序中所有指令的CPI,指令系统中某一类指令的CPI等
IPC:CPI的倒数
MIPS(Million Instructions Per Second):每秒钟CPU能执行的指令总条数(单位:百万条/秒)

CPU时间

第二章 数据表示
机器数及特点
真值:符号用“+”“-”表示
机器数:符号数值化,用0,1表示符号
原码
反码
补码
移码

定点与浮点数据表示
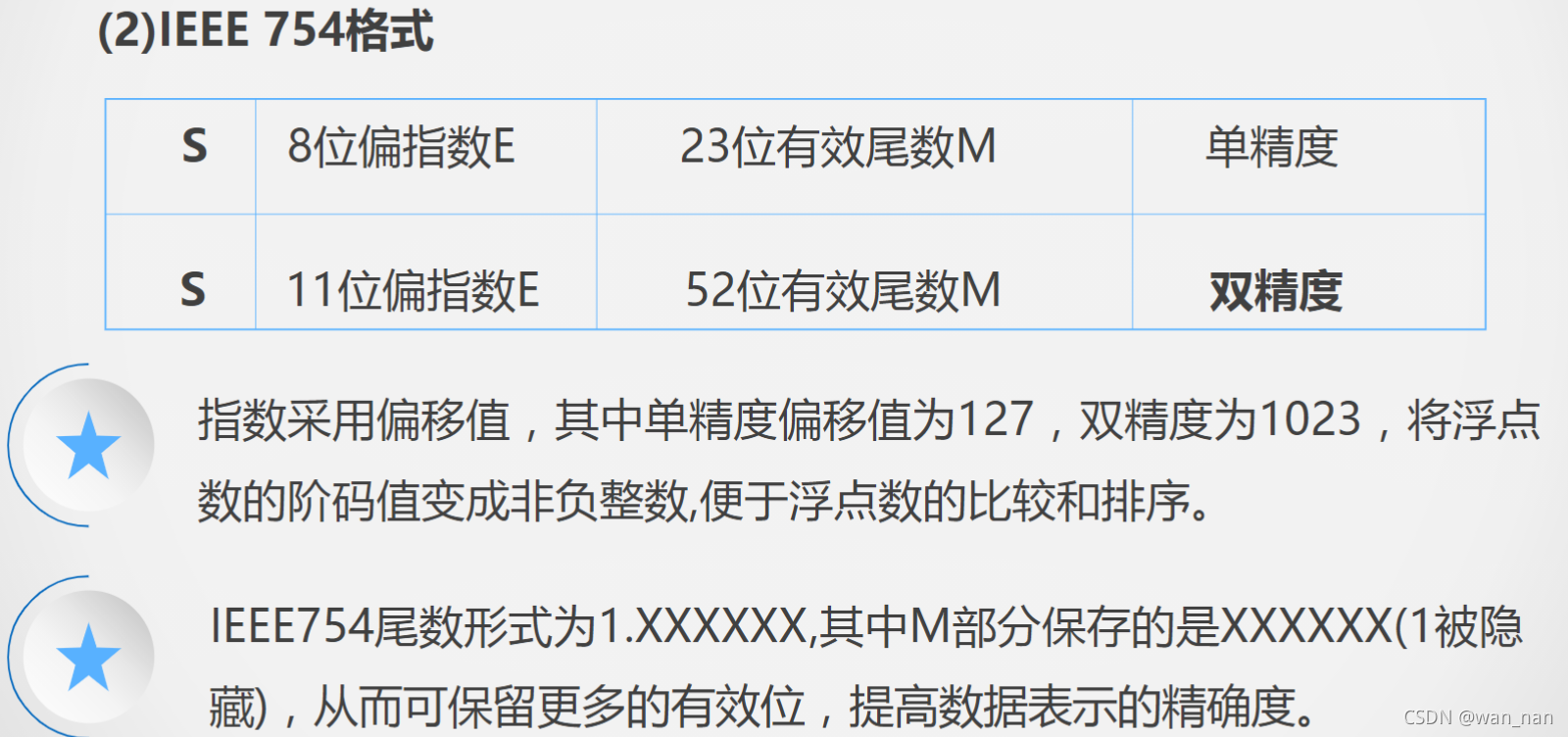
IEEE 754格式
数据校验的基本原理
增加冗余码(校验位)
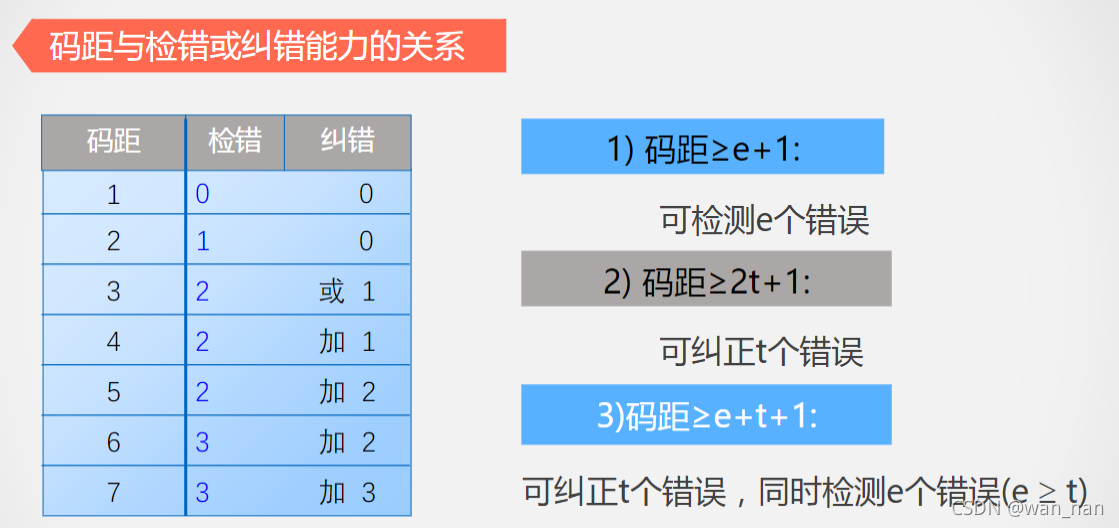
码距:同一编码中,任意两个合法编码之间不同二进制位数的最小值
校验码中 增加冗余项 的目的就是为了增大码距
码距与检错纠错能力的关系
选择码距要考虑的因素

奇偶校验
- 编码与检错简单
- 编码效率高
- 不能检测偶数位错误,是一种错误检测码
- 不具备纠错能力
- 改进的奇偶校验:
- 交叉奇偶校验
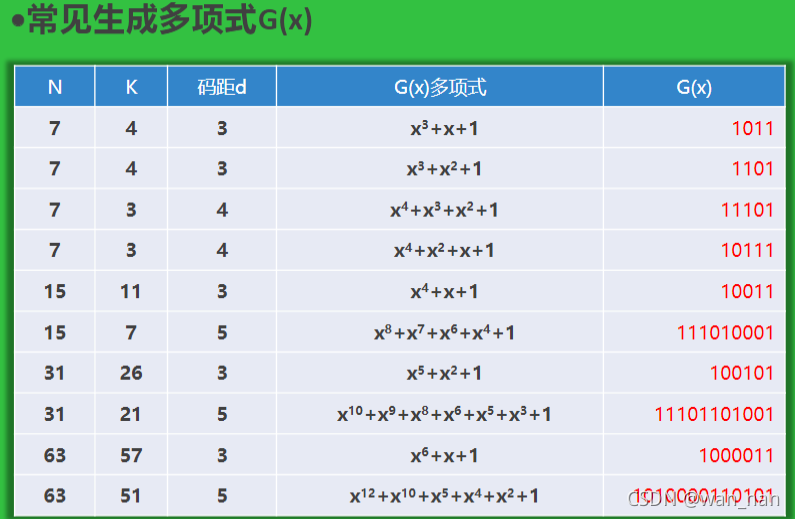
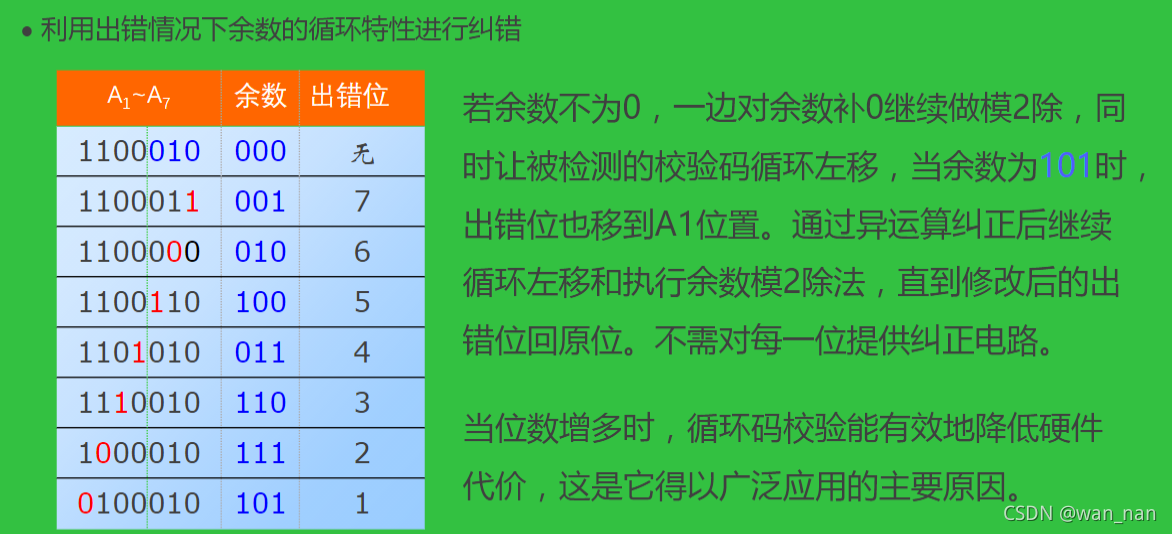
CRC循环冗余校验
“循环”指模2运算得到的余数循环

r位校验位可以表示2^r种状态,减去一种没有错误的状态,剩余2^r-1种错误
模2运算规则

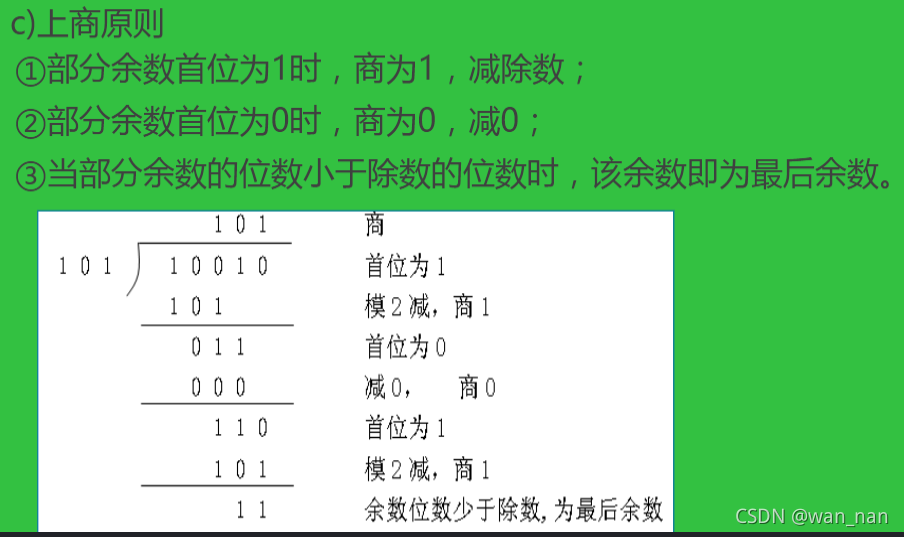
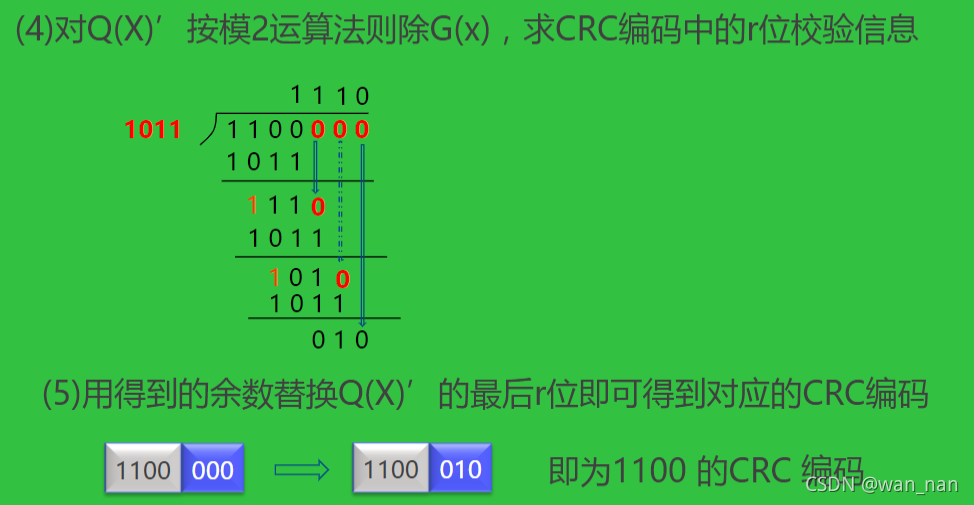
求CRC编码5步

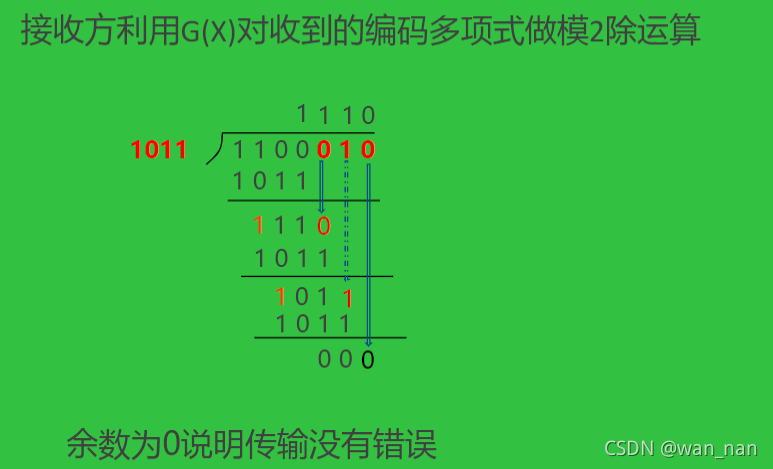
CRC检错
不同位出错,模2除运算得到的余数不同
采用不同的多项式,对应的相同位出错时,得到的余数不一定相同
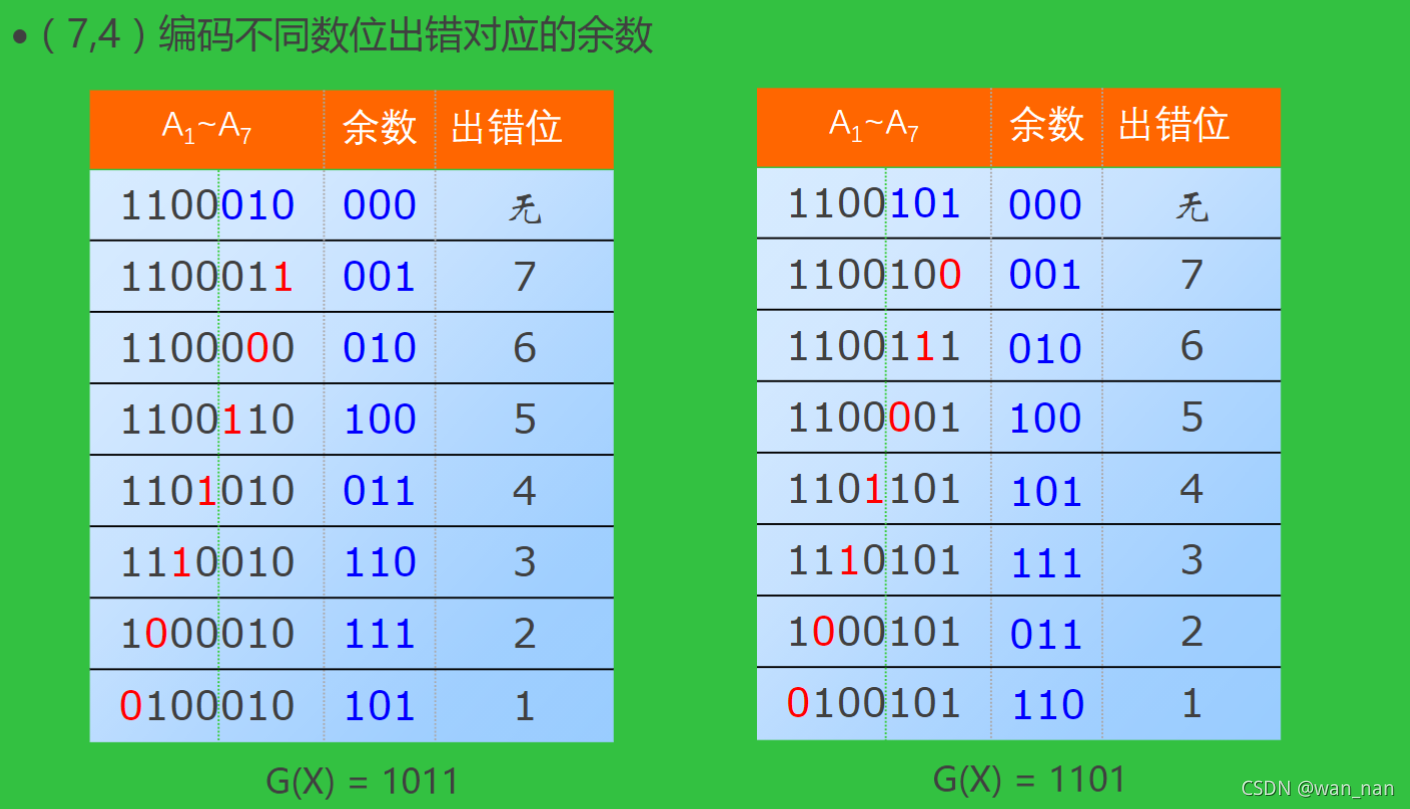
CRC纠错
海明校验
有效信息k位,校验信息r位,应满足N=k+r<=2^r-1
校验位和数据位分布位置


Pi由Pi所检验的位 异或 得到
Gi由Pi和Pi所校验的位 异或 得到的
海明码特点
- 指错字全为0不一定无错
- 不一定能区别一位错和两位错
可以通过在海明校验的基础上增加一位奇偶校验位,来区分是一位错还是两位错
题目
2.2(7)
float(即IEEE 754单精度浮点数格式)能表示的最大正整数
- 阶码最大为11111110,全为1为无穷
- 尾数部分全为1时 可以表示为(2-2^(-r)),r为1的位数
第三章 运算方法与运算器
溢出
运算结果超出了某种数据类型的表示范围(溢出只可能发生在同符号数相加时
- 溢出的检测:
- 对操作数和运算结果的符号位进行检测,符号不同表明发生了溢出
- ==对最高有效数据位进位和符号位进位进行检测,两者异或结果为1时表明发生溢出==
- 变型补码,基于双符号位的溢出检测,正常的正数符号位为00,负数符号位为11,若运算结果符号位为10或01,则发生溢出
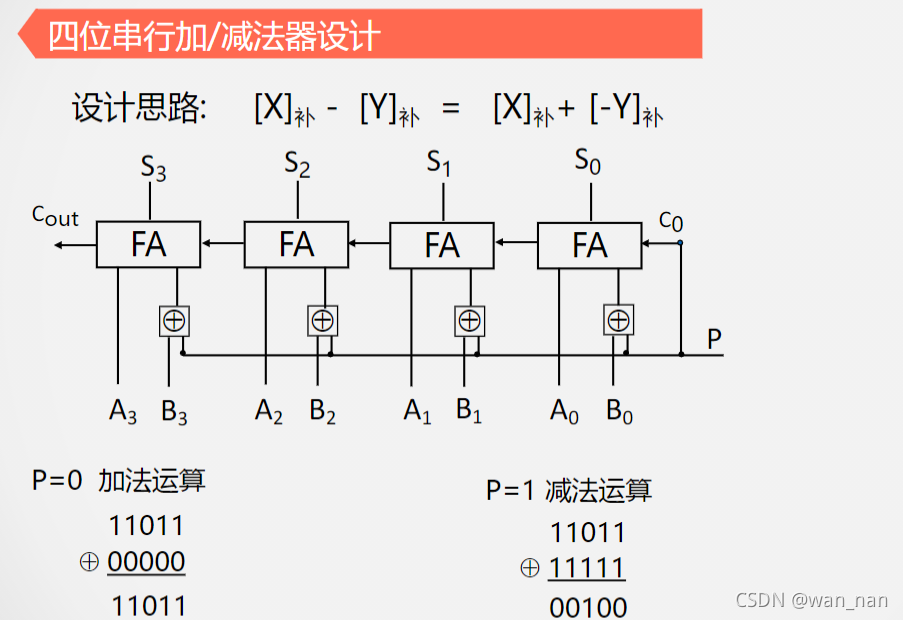
定点数补码加减
四位串行加/减法器设计
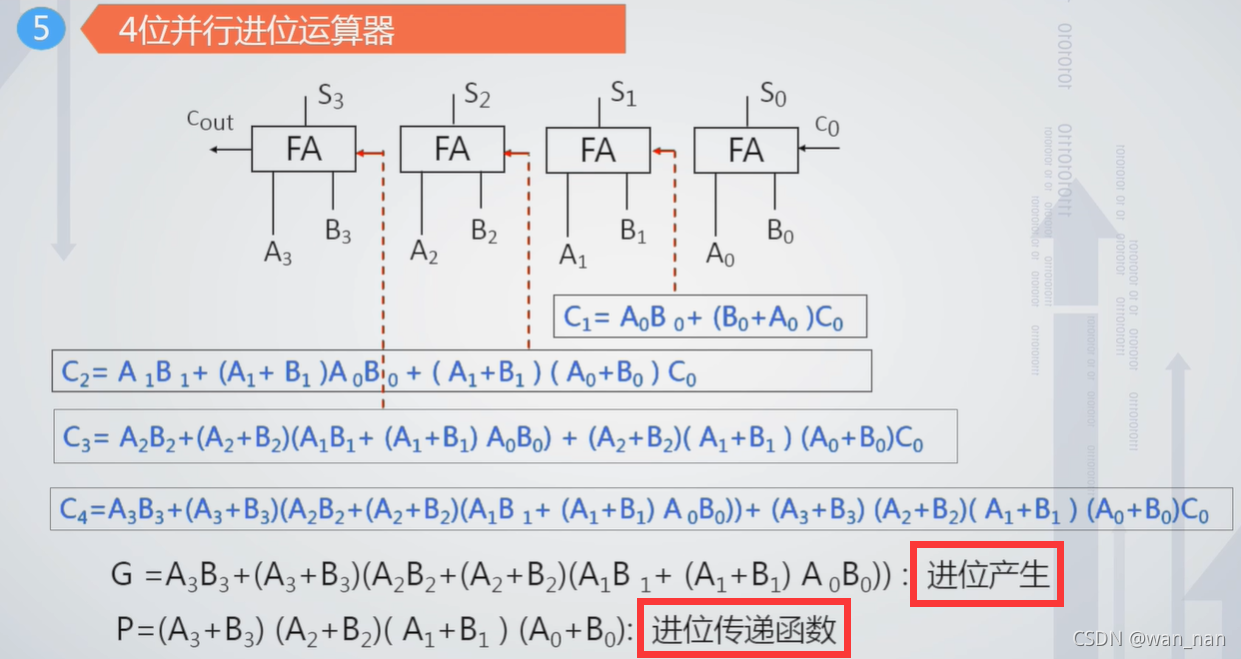
四位先行进位

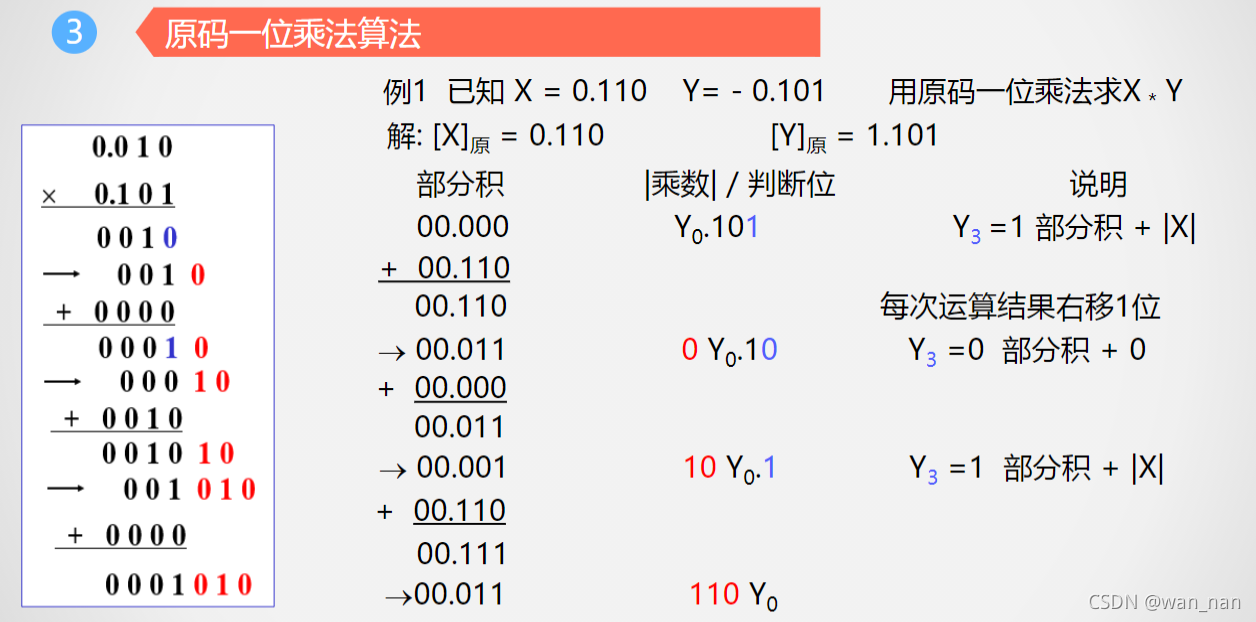
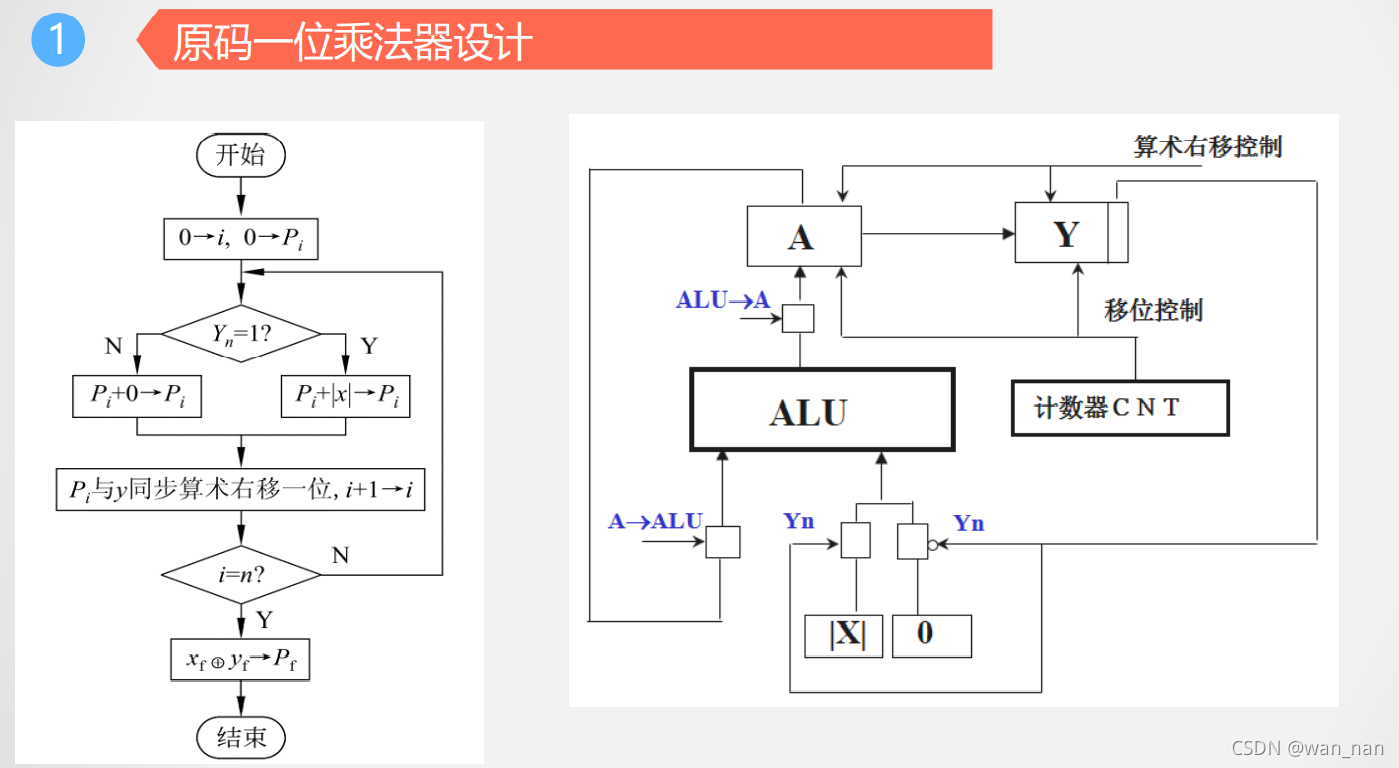
原码一位乘法
举例:
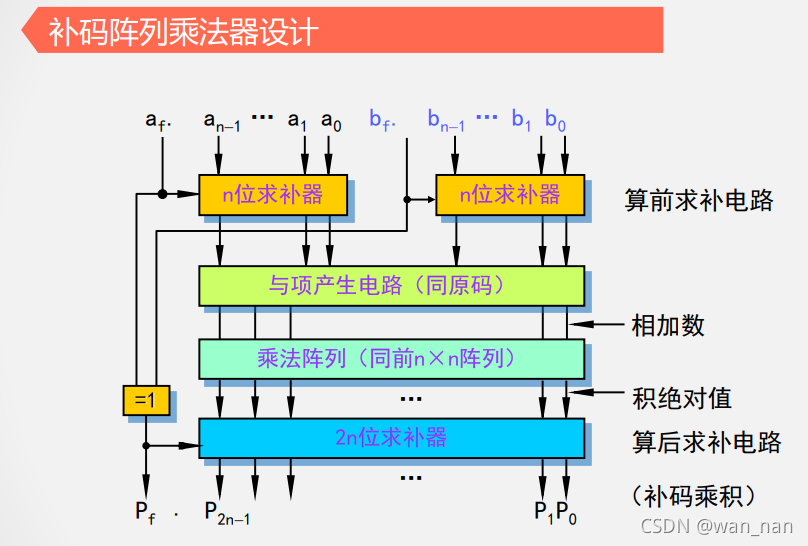
补码一位乘法



- 课本P74例题也可以参考

-
乘法运算器设计
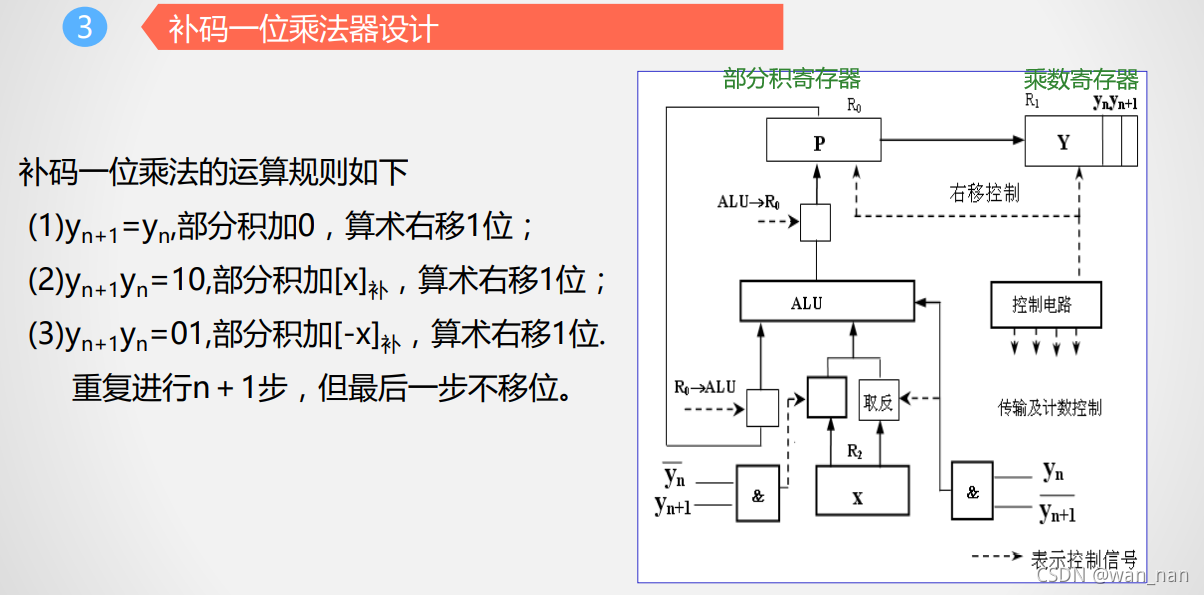

y(n)=1,y(n+1)=0时,加的是[-x]补,所以A为取反电路,虚线为控制信号,实线为加一,[x]补取反加一即为[-x]补

定点数除法
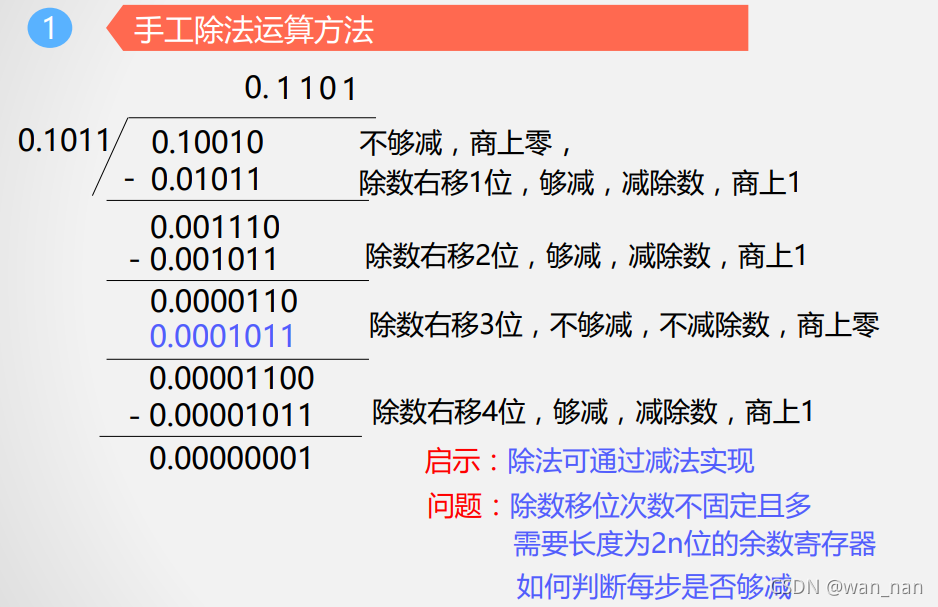
原码恢复余数除法
方法:

例子:


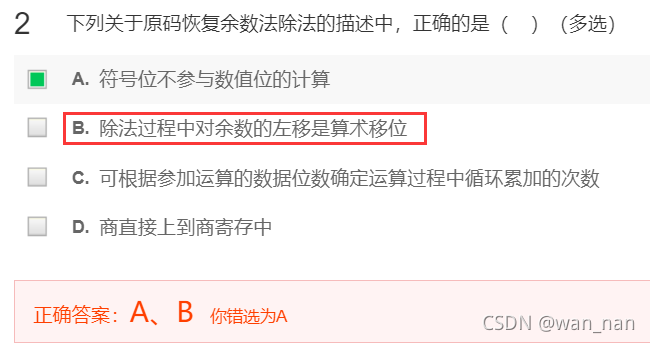
除法过程中对余数的左移是算术移位
所上商要通过左移操作才能移到商寄存器中
原码加减交替法(不恢复余数法)

下例中,左移的次数和上商的次数都是确定的,而恢复余数法无法确定
每次加Y/减Y比较后都要上商,结果大于零上1,结果小于零上0

由上例,运算器的进位输出位和上商位相同,于是可以用进位输出当做上商位的控制信号
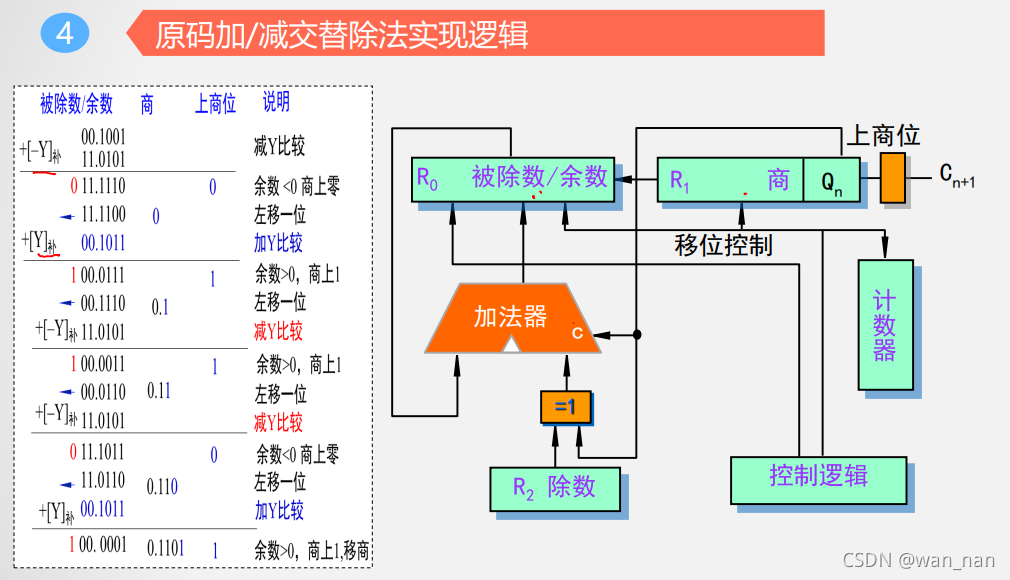
如果是小数除法,要求被除数的绝对值小于除数的绝对值
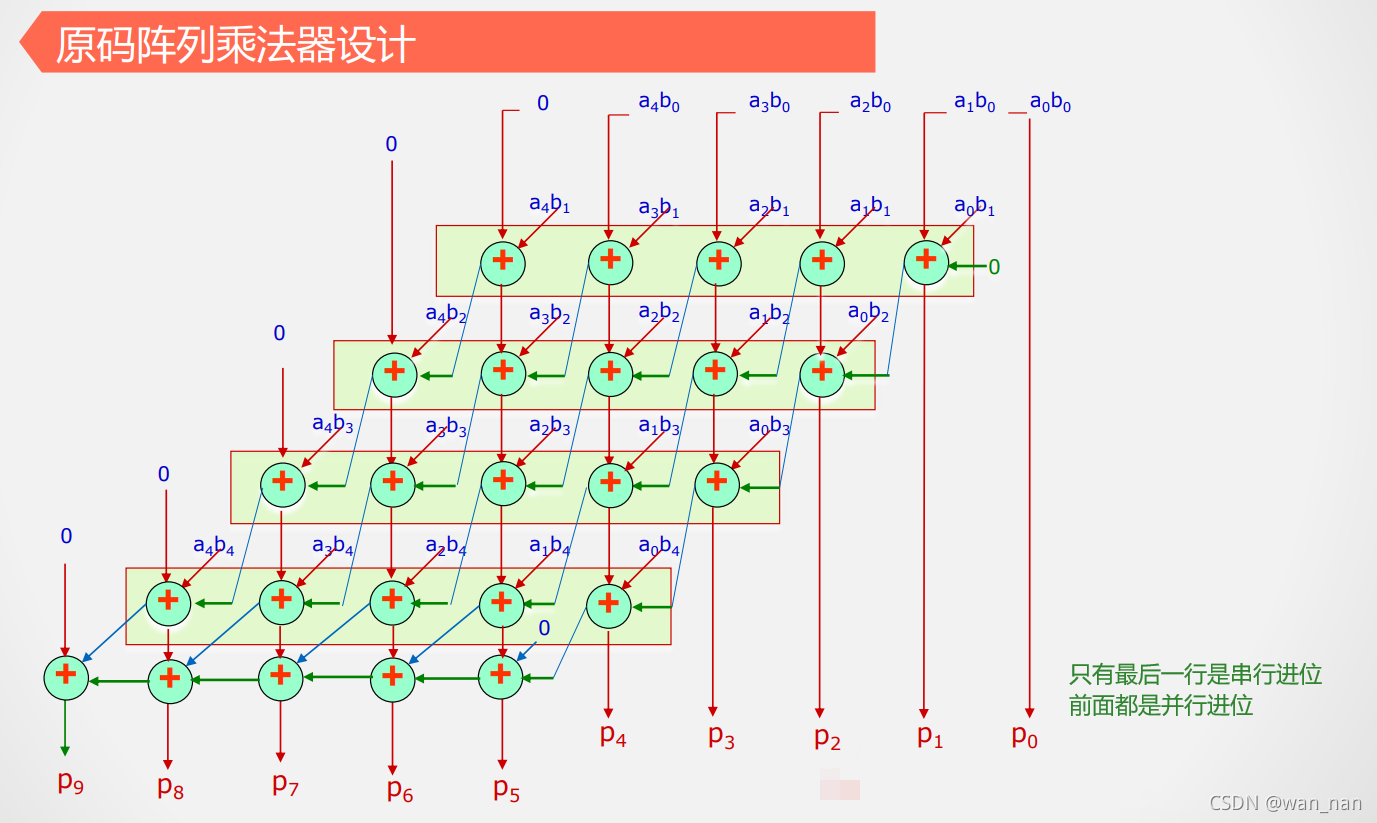
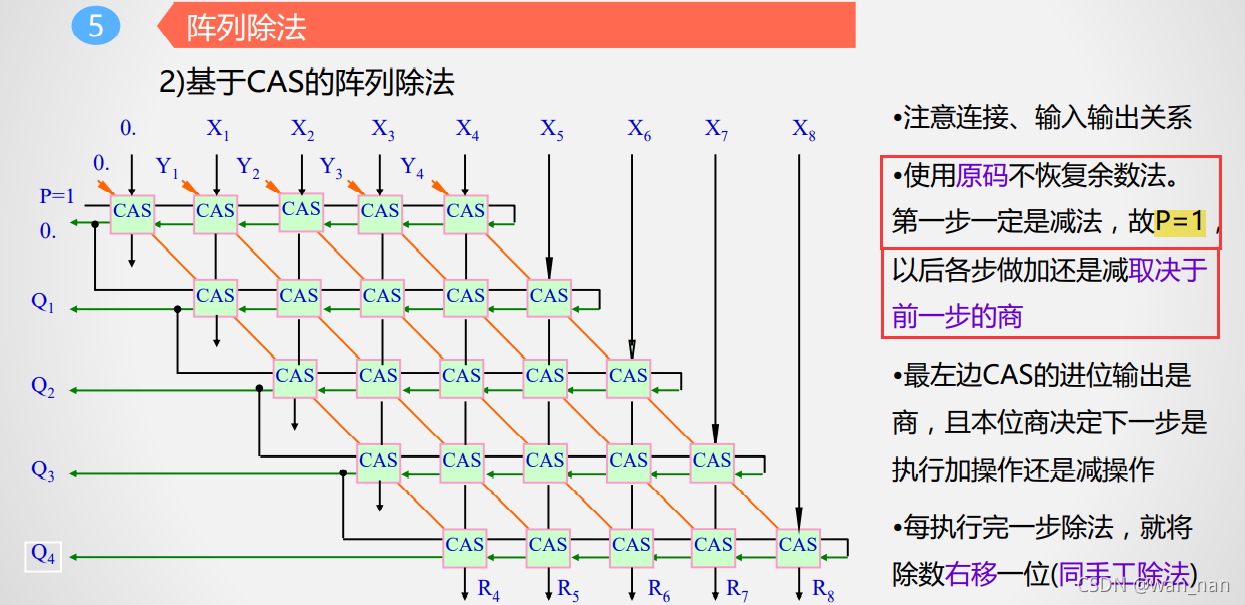
阵列除法
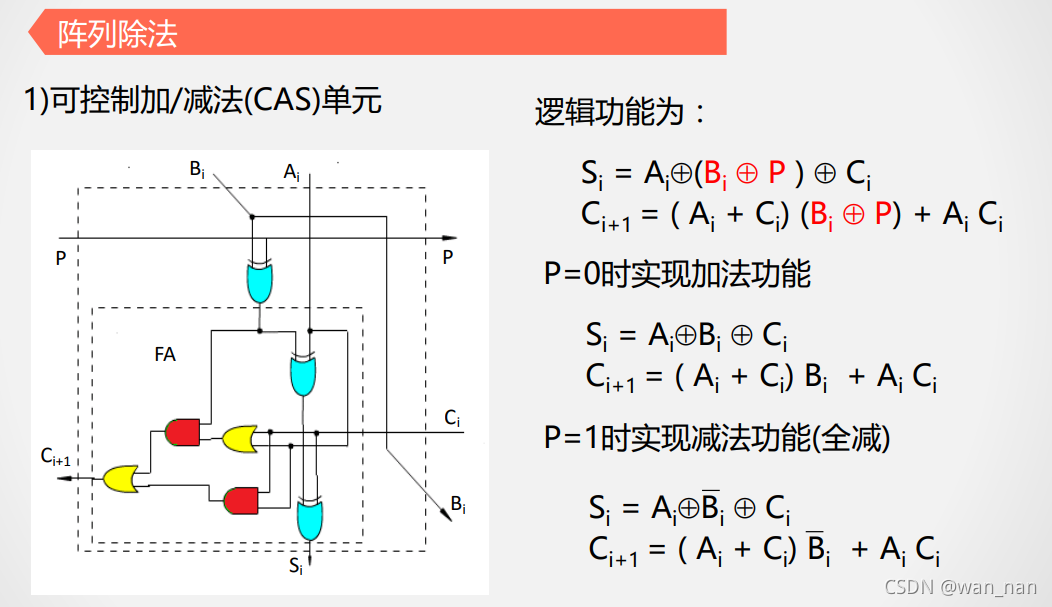
阵列除法器**是将除数右移**,与手工除法相同,而不恢复余数法是将除数左移
且右移是通过连接方式的错位连接实现,并未使用移位寄存器,不会占用时间去移位
补码交替除法
一道题

浮点数加减运算
规格化浮点数的尾数形式:00.1或11.0
规格化方法:

运算步骤
阶码和尾数记得都要带双符号位


题目

最终答案是D,会在尾数规格化的时候,尾数右移,阶码加一,导致阶码溢出(阶码从00111加一变为01000溢出)
第四章 存储系统
存储系统的层次结构
哈弗结构 (Harvard Architecture)是指:数据和指令分别存放
存储体系层次化结构的理论基础:局部性原理

存储系统层次结构由Cache 、主存、辅助存储器三级体系构成
加剧CPU和主存之间速度差异的原因:
- 由于技术与工作原理不同,CPU增速度明显高于主存增速率
- 指令执行过程中CPU需要多次访问主存
主存中的数据组织
存储字长:主存的一个存储单元所包含的二进制位数
数据存储与边界的关系:
对于按边界对齐的数据存储:
int i,short k,double x,char c,short j
大端 与 小端


静态存储器的工作原理
SRAM存储单元

无论读写,都要求X和Y译码线同时有效,5/6/7/8四个管通
对任何一个SRAM存储单元的读写,一定需要通过对应的行选通和列选通信号使与该存储单元对应的4个门控管都处于选通状态写过程:
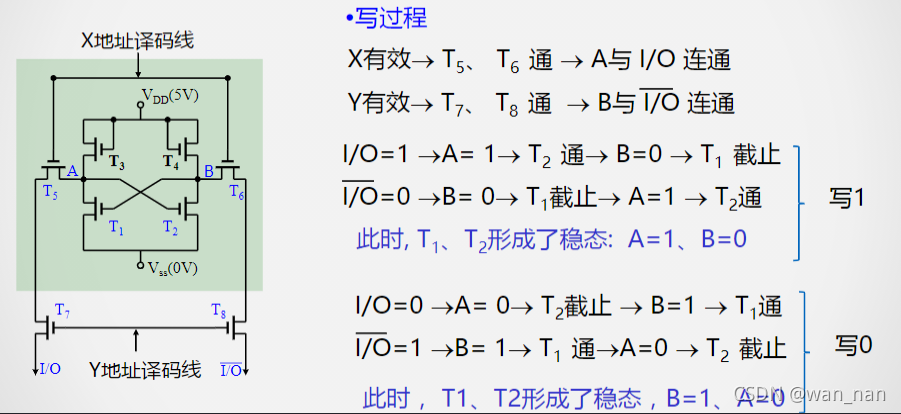
读过程(根据电流放大器中的电流方向判断读出的是1还是0)

保持:
X、Y撤销后,负载管T3、T4分别为工作管T1、T2提供工作电流,保持其稳定互锁状态不变
保存1时,T2、T4要导通
保存0时,T1、T3要导通
静态存储器的结构
单译码结构-双译码结构
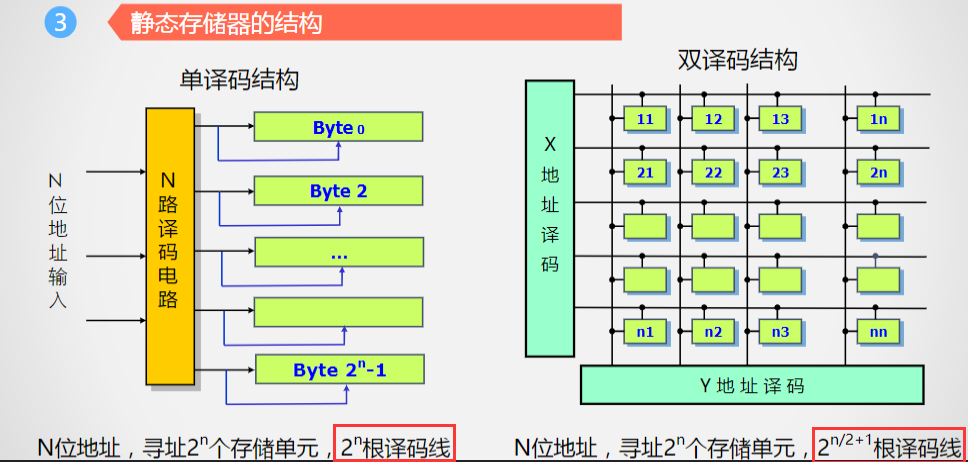
6116存储器:
行列地址的位数要看内部结构

2114存储器:
2114的读写控制比6116更简单

题目
t1:

t2:
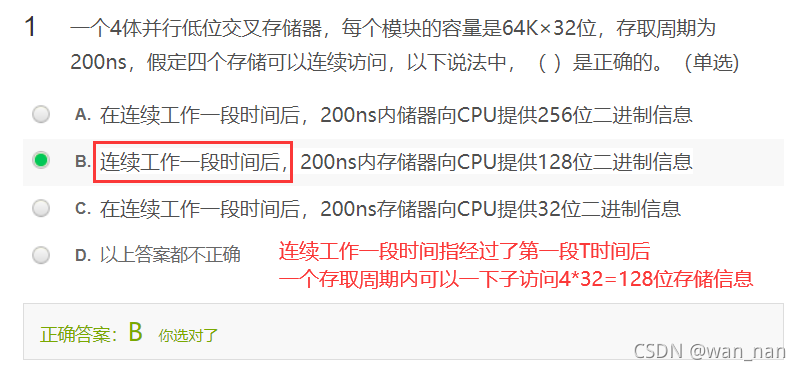
一个容量为16K*32位的存储器,其地址线和数据线的总和为:46
因为容量为16K=2^14,所以说地址线的数目为14根,又因为32位,所以说数据线的根数为32根,所以说地址线与数据线的总和为46根。
动态存储器的工作原理
- SRAM静态存储单元的不足:
- 晶体管过多(每个单元需要6个晶体管)
- 存储密度低
- 功耗过大
(意识到这样截图真的耗时)
以后决定以课后题驱动知识的学习
DRAM基本结构
写操作
读操作
比写复杂,速度比静态存储器更慢
保持操作
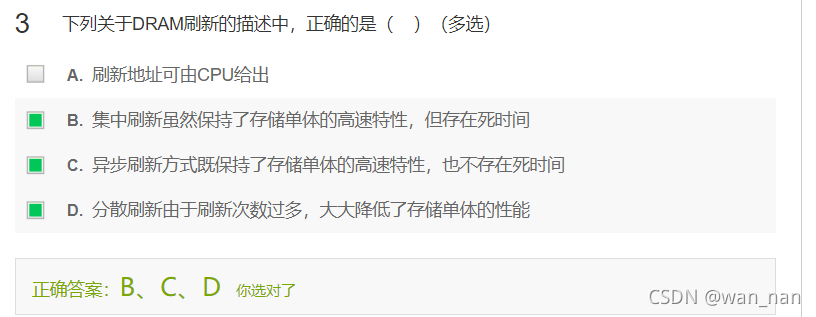
刷新操作
集中刷新(实时应用不适用,存在死时间)
分散刷新(刷新变多使读写性能降低,存在死时间)
异步刷新(将刷新周期分为DRAM行数个部分)
刷新按照行刷新,不需要列选通信号
刷新地址由刷新地址计数器控制,不由CPU控制
DRAM通过地址复用技术(片选信号选择),使得需要的地址线数量降为原来的一半
地址复用,ras信号有效时,DRAM收到的地址是行地址;cas信号有效时,收到的是列地址
行列地址复用:比如你的存储器容量是16bit,那么可以将这16个比特组织成一个4*4的矩阵,为了找到某个你想要找的bit,比如第1行第2列的那个bit。你先发送二进制的01,表示要找的数据在第1行;接着发送二进制的10,表示要找的数据在第2列。这样一来你就找到了第1行第2列的那个bit。可以发现只要两根地址线就能寻找16个bit了,但是要发送两次地址(一次行地址,一次列地址)

刷新操作的定义:
定时刷新的原因:由于存储单元的访问是随机的,有可能某些存储单元长期得不到访问,不进行存储器的读/写操作,其存储单元内的原信息将会慢慢消失,为此,必须采用定时刷新的方法,它规定在一定的时间内,对动态RAM的全部基本单元电路必作一次刷新,一般取2ms,即刷新周期(再生周期)
所以读操作也有刷新功能
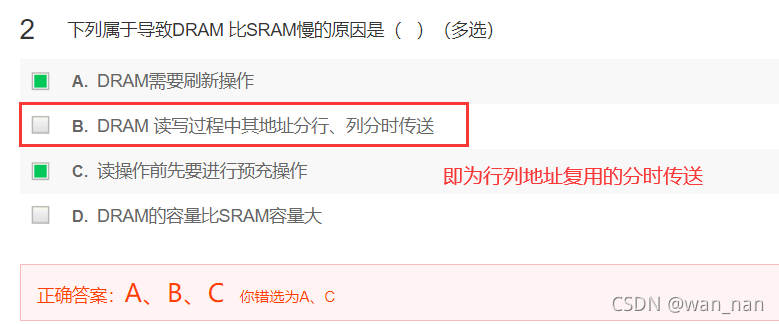
为什么动态存储器比静态存储器慢
静态存储变量通常是在变量定义时就分定存储单元并一直保持不变, 直至整个程序结束。
动态存储变量是在程序执行过程中,使用它时才分配存储单元, 使用完毕立即释放。 典型的例子是函数的形式参数,在函数定义时并不给形参分配存储单元,只是在函数被调用时,才予以分配, 调用函数完毕立即释放。如果一个函数被多次调用,则反复地分配、 释放形参变量的存储单元。
存储扩展
[MOOC链接](https:// www.icourse163.org/learn/HUST-1003159001?tid=1465053441#/learn/content?type=detail&id=1243767075&sm=1)
常见的有三种:
- 位扩展
- 字扩展
- 字位扩展
要完成CPU与主存间地址线、数据线、控制线的连接
整数边界存放问题(?)
32位存储器 选取地址线的 A15~2
多体交叉存储器
其基本思想是在不提高存储器速率、不扩展数据通路位数的前提下,通过存储芯片的交叉组织,提高CPU单位时间内访问的数据量,从而缓解快速的CPU与慢速的主存之间的速度差异
高位多体交叉存储器
低位多体交叉存储器
相邻地址处于不同存储体中
每个存储体均需地址寄存器
性能提升
扩充容量方便
可以实现多个存储体的并行流水线访问
提高访问速度
局部性原理:
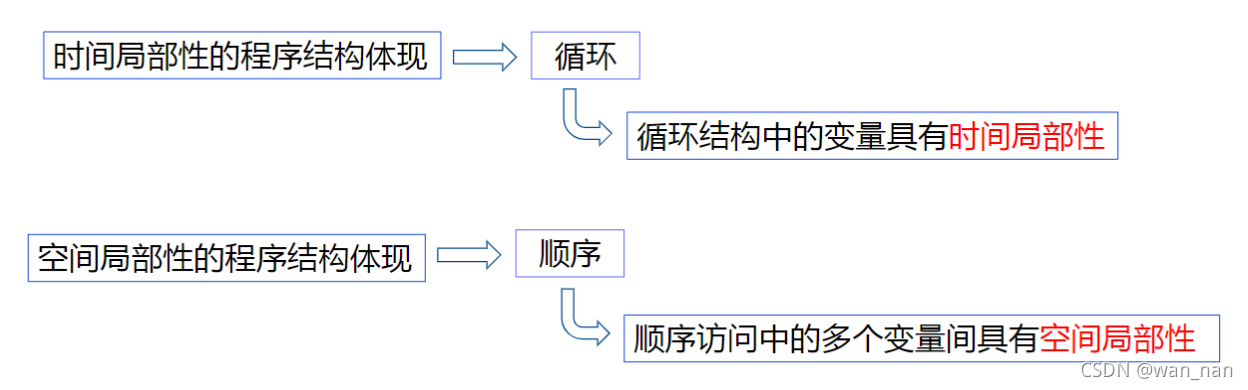
时间局部性(Temporal Locality):如果一个信息项正在被访问,那么在近期它很可能还会被再次访问。
程序循环、堆栈等是产生时间局部性的原因。
空间局部性(Spatial Locality):在最近的将来将用到的信息很可能与正在使用的信息在空间地址上是临近的。
顺序局部性(Order Locality):在典型程序中,除转移类指令外,大部分指令是顺序进行的。顺序执行和非顺序执行的比例大致是5:1。此外,对大型数组访问也是顺序的。
指令的顺序执行、数组的连续存放等是产生顺序局部性的原因。

Cache基本原理
cache的理论基础:
局部性原理
CPU读操作有命中和缺失两种结果
写操作有两种策略
写穿策略:将数据写入缓存,同时立即写入主存中
写回策略:(能体现cache的高速特性,但会面临和读操作相同的困境)不会立即将数据写入到主存中,修改会在缓存中堆积一段时间,直到该数据块将被驱逐出缓存时才写入到主存中
cache地址映射
脏位和有效位

脏位(Dirty)用于判断主存的相关数据是否有效
有效位(Valid)用于判断Cache的数据是否有效

相联存储器
前面介绍的存储器都是按地址访问的存储器,而相联存储器则是按内容访问的存储器
作用:判断CPU要访问的内容是否在cache中
相联存储器:硬件并发查找
CPU给出要找的主存地址
根据不同规则抽取主存地址的部分内容作为查找依据(关键字)(进行标志位剥离后交给多路并发比较电路)
比较电路与cache相应部分的标志位进行并发比较
命中则取出


存储体:由高速半导体存储器构成,以求快速存取。

是并发比较而非并行访问
Cache地址映射与变换方法
主存数据映射至cache的三种方式:
全相联(二维)
主存的数据块可映射到cache的任意行,同时将该数据块地址对应行的标记存储体中保存
- Cache利用率高
- 块冲突率低
- 淘汰算法复杂
- 适用于小容量cache

直接相联(三维)
主存分块后将以cache行数为标准进行分区
映射算法:
Cache共n行,主存第j块号映射到Cache 的行号为:
$i=j\ mod\ n$
即主存的数据块映射到Cache特定行

相应行已经被占用时会用新的数据替换
特点:
- cache利用率低
- 块的冲突率高
- 淘汰算法简单
- 适合于大容量的cache
直接相联映射方式下,根据Cache大小将地址划分为标记(Tag)、索引(Index)和块内偏移地址三部分。其中Index指向Cache特定行位置(√)
==组相联(三维)==
主存分块,块的行数为Cache行数(Line ),两者大小相同
Cache分组(每组中包含k行),本例假定K=4
主存分块后还要以cache组数为标准进行分组,所谓组相联,即为主存组与cache组之间的映射
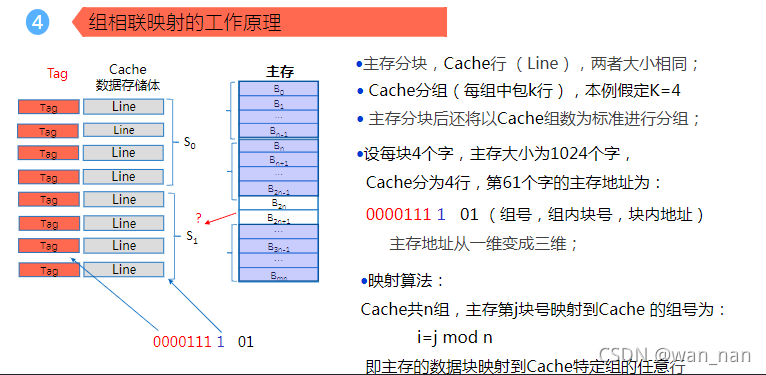
组相联映射到cache的特定组的任意行
特点:
cache利用率
块冲突率
淘汰算法复杂度
- 均处在全相联和直接映射之间
- 使用场合也折中
K路组相联是指Cache被分成K组(×)
是指cache每组有K行
==若组相联中:cache只分成了一组,则组相联退化为全相联==
==若组相联中:cache分的组数与cache的行数相同,即每组只有一行,则组相联退化为直接映射==
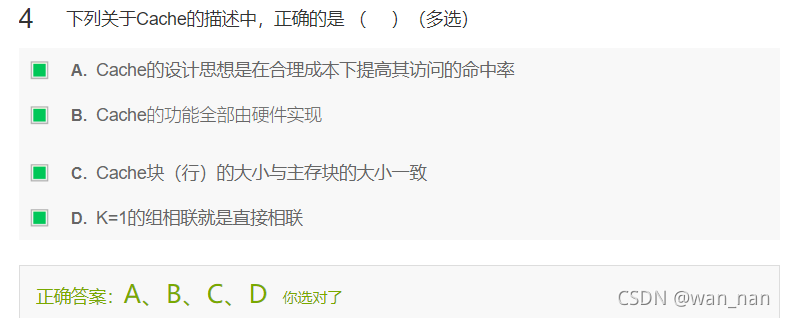
cache全部由硬件实现
tips:“块”经常被用来指“行”
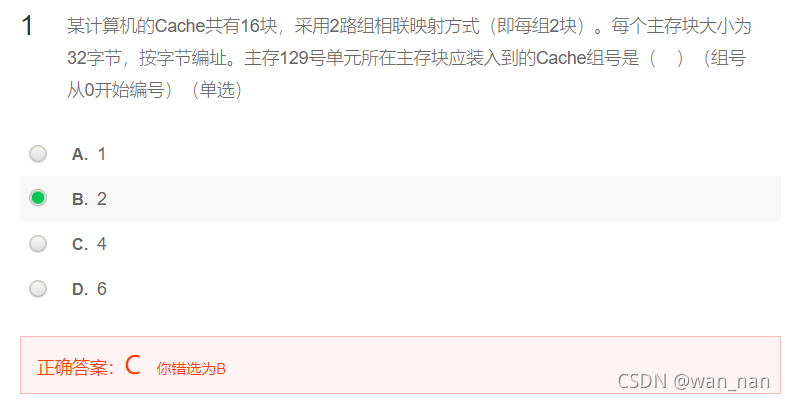
==组相联的坑,解答==
替换算法
程序运行一段时间后,Cache存储空间被占满,当再有新数据要调入时,就需要通过某种机制决定替换的对象
几种常见的替换算法
先进先出法-FIFO(First in First out)
借用计数器确定 先进的行
最不经常使用法—LFU (Least Frequently Used)
使用:命中一次表示使用一次
同样通过计数器确定使用次数少的行
当使用次数最小的行不止一个时,可以结合其他方法使用
近期最少使用法—LRU(Least recently used )
新调入或命中的行计数值会清零,其他行加一
随机替换法
抖动特性:刚调出的行就被访问
要保证高速特性:需要硬件和软件的配合
==Cache例题==
例1

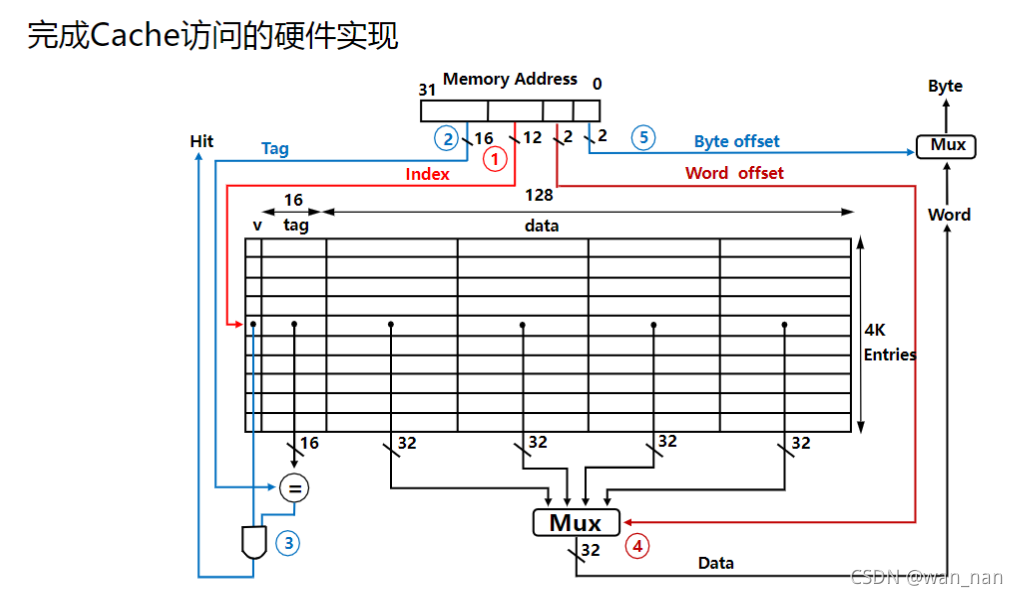

==例2==

16KB/32B=512
1K就默认为**$2^{10},而非1024$**

用上了cache后的加速比


时间局部性(Temporal Locality):如果一个信息项正在被访问,那么在近期它很可能还会被再次访问。
程序循环、堆栈等是产生时间局部性的原因。
空间局部性(Spatial Locality):在最近的将来将用到的信息很可能与正在使用的信息在空间地址上是临近的。
由上可知:


虚拟存储器
概述
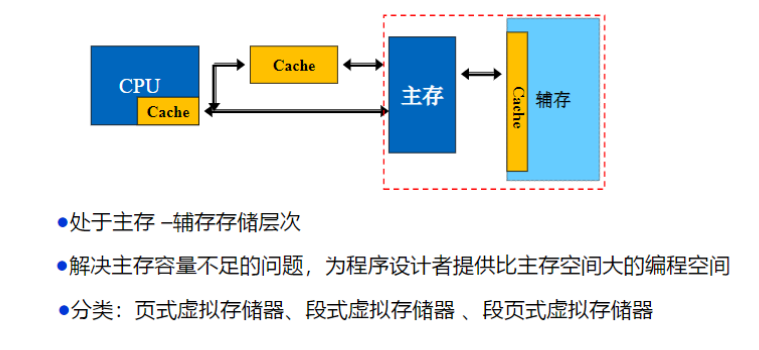
解决主存容量不足的问题,此时主要依靠辅存
计算机通过辅存实现虚拟存储器,来执行比主存更大的程序
所以计算机无法执行比辅存更大的程序
虚拟存储器必须解决:
CPU访问存储系统的地址属性?
主存是物理地址空间,辅存是逻辑地址空间
使用哪种地址访问?访问哪里?如何转换?
如何判断CPU要访问的信息是否在主存中?
采用MMU:(MMU在CPU内)管理虚拟存储器和物理存储器
对于页式虚拟存储器来说,采用页表来判断CPU要访问的内容是否在主存,同时页表与MMO配合实现逻辑地址和物理地址之间的转换
虚拟存储器地址划分
==页表放在主存中==

逻辑地址和物理地址的转换
如下图所示:
页表第一位为有效位,表示该页是否在主存中
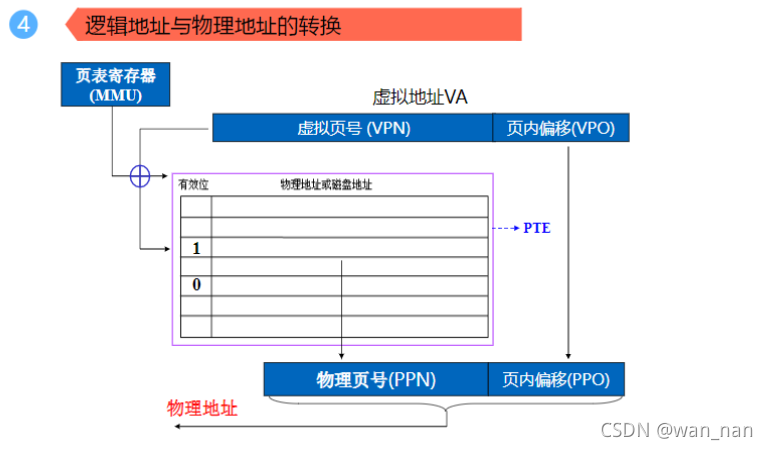
==举例计算:==

页式虚拟存储器中,虚拟页的容量与主存物理块的容量相同
错题:

虚拟地址位数:虚拟存储器容量为4G,4G=2^32^,即为32位
物理地址位数:主存容量为512M,512M=2^29^,即为29位
页内偏移地址位数:由页大小为8k=2^13^,即为13位
虚拟地址=虚拟页号+页内偏移,故虚拟页号的位数有32-13=19位,项数为2^19^项
TLB
为什么需要TLB
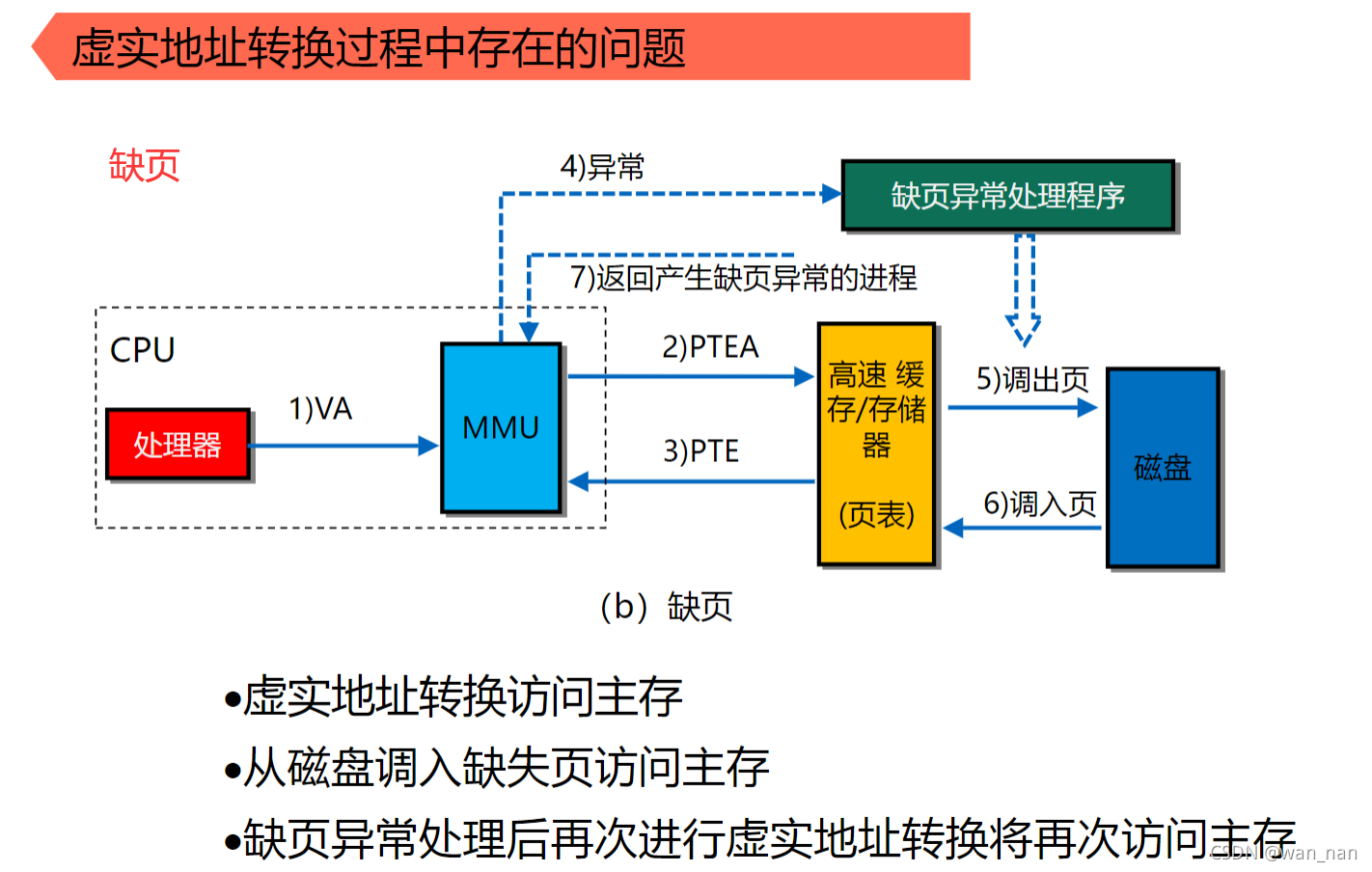
虚实地址转换时需要访问主存中的页表,访问主存是很耗时的,因为cache的高速特性得不到发挥
缺页-找到的页不在主存中-缺页异常处理程序-将存放在辅存中的调入到主存中
调入后,要重新走一边查找的流程,重新查找一次页号
TLB的工作原理
TLB的内容可以看做页表变化后的子集
原理类似cache

基于TLB的虚拟地址到物理地址的转换:
本过程不需要访问主存,全程在TLB中进行
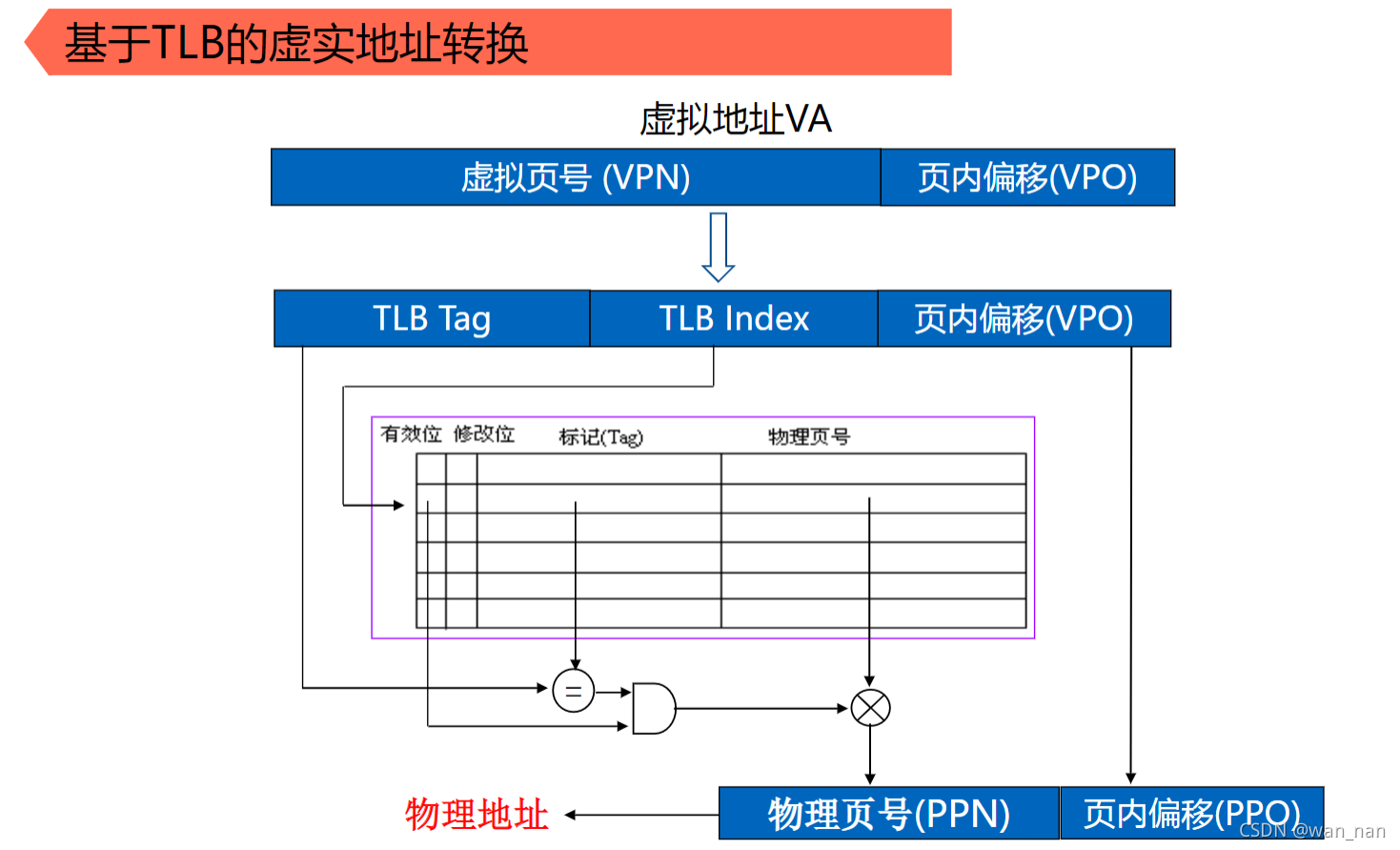
VPN:虚拟页号
VPO、PPO:页内偏移
VA:虚拟地址=VPN+VPO
PPN:物理页号
PA:物理地址=PPN+PPO

**==题目==**:
TLB中存放的是页表项
TLB的工作原理是局部性原理
CPU基于虚地址访问TLB(×)
虚地址VA被拆分得到虚拟页号VPN,用虚拟页号访问TLB
TLB的功能由硬件实现(√)
RAID
将多个物理磁盘合并成大的逻辑盘
将数据条带化后存放在不同磁盘上,通过多磁盘的并行操作提高磁盘系统的读写速率(提速)
使用基于异或运算为基础的校验技术,恢复损坏的数据
使用校验盘
RAID0
数据以条带方式均匀分散在各磁盘

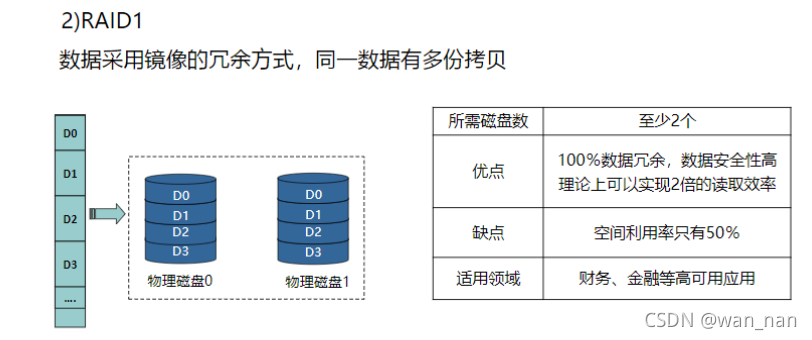
RAID1
采用镜像的冗余方式,同一数据有多份拷贝
RAID3/4
数据按位/条带并行传输道多个磁盘上,同时校验数据存放到专用校验盘上

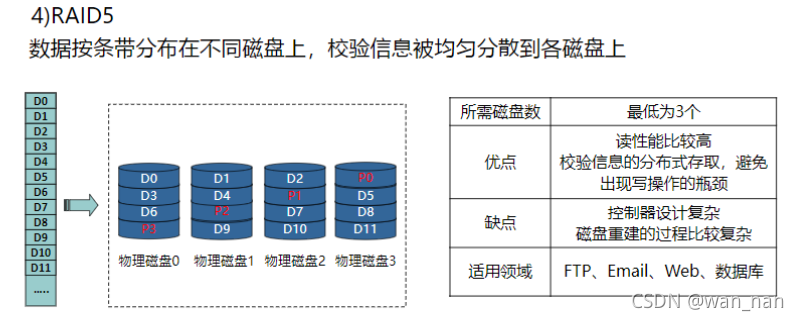
RAID5
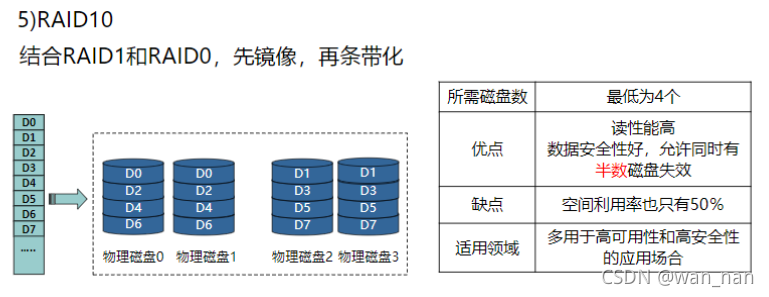
RAID10(一零)
冗余度为2
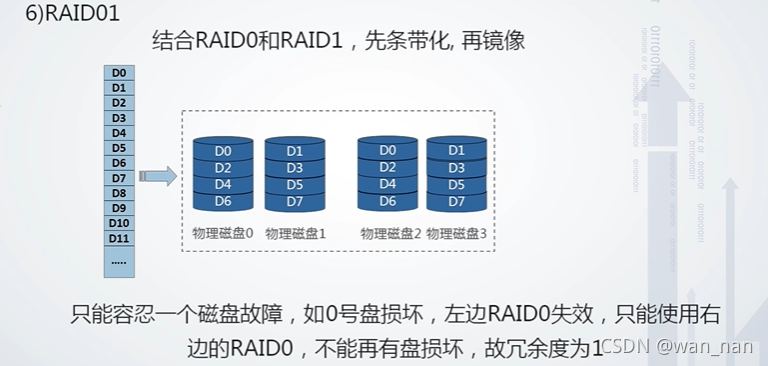
RAID01(零一)
冗余度为1
总结

第五章 指令系统
调用者保存寄存器:
也叫易失性寄存器,在程序调用的过程中,这些寄存器中的值不需要被保存(即压入到栈中再从栈中取出),如果某一个程序需要保存这个寄存器的值,需要调用者自己压入栈;
(临时变量)
被调用者保存寄存器:
也叫非易失性寄存器,在程序调用过程中,这些寄存器中的值需要被保存,不能被覆盖;当某个程序调用这些寄存器,被调用寄存器会先保存这些值然后再进行调用,且在调用结束后恢复被调用之前的值;
(全局变量)
为了减少开销,应该优先使用调用者保存寄存器
中断服务程序:没有调用者,所以凡是中断处理器用到的寄存器都要保存,不管是哪种寄存器
寻址
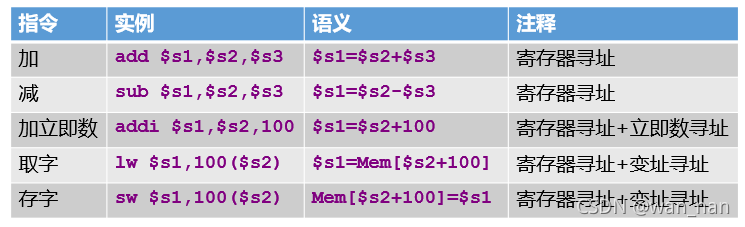
零号寄存器可以实现寄存器传送和立即数传送
在函数嵌套中,凡是后需要被覆盖的寄存器,都要事先保存并后续恢复
MIPS指令系统很简单,x86中一条指令完成的工作可能需要多条MIPS指令来实现
指令通常分为:
操作码字段+寻址方式字段+地址码字段(寻址方式+地址码=操作数字段)
操作码长度决定系统的规模
寻址方式字段长度与寻址方式种类有关,有可能隐藏在操作码字段
指令字长度
指令中包含的二进制码的位数
指令字越长,地址码长度越长,可直接寻址空间就越大;但也会导致占用空间变大,取指令变慢
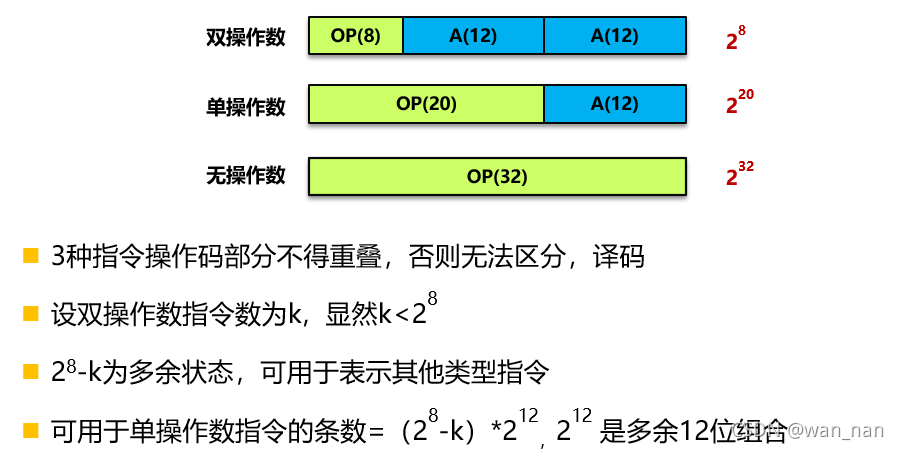
扩展操作码

指令寻址
除了指令寻址还有操作数寻址
顺序寻址

跳跃寻址
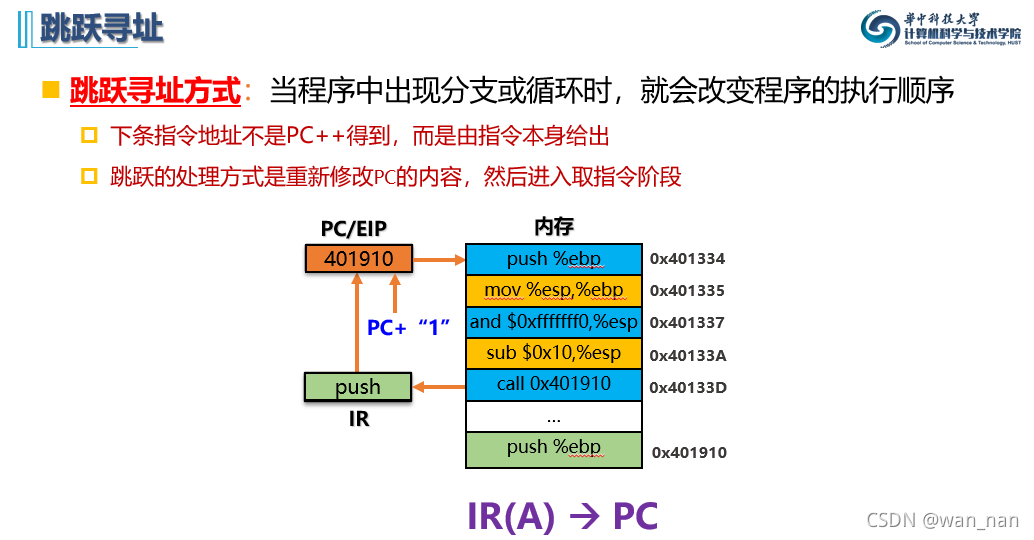
第六章 中央处理器
CPU概述

指令执行一般逻辑

指令周期
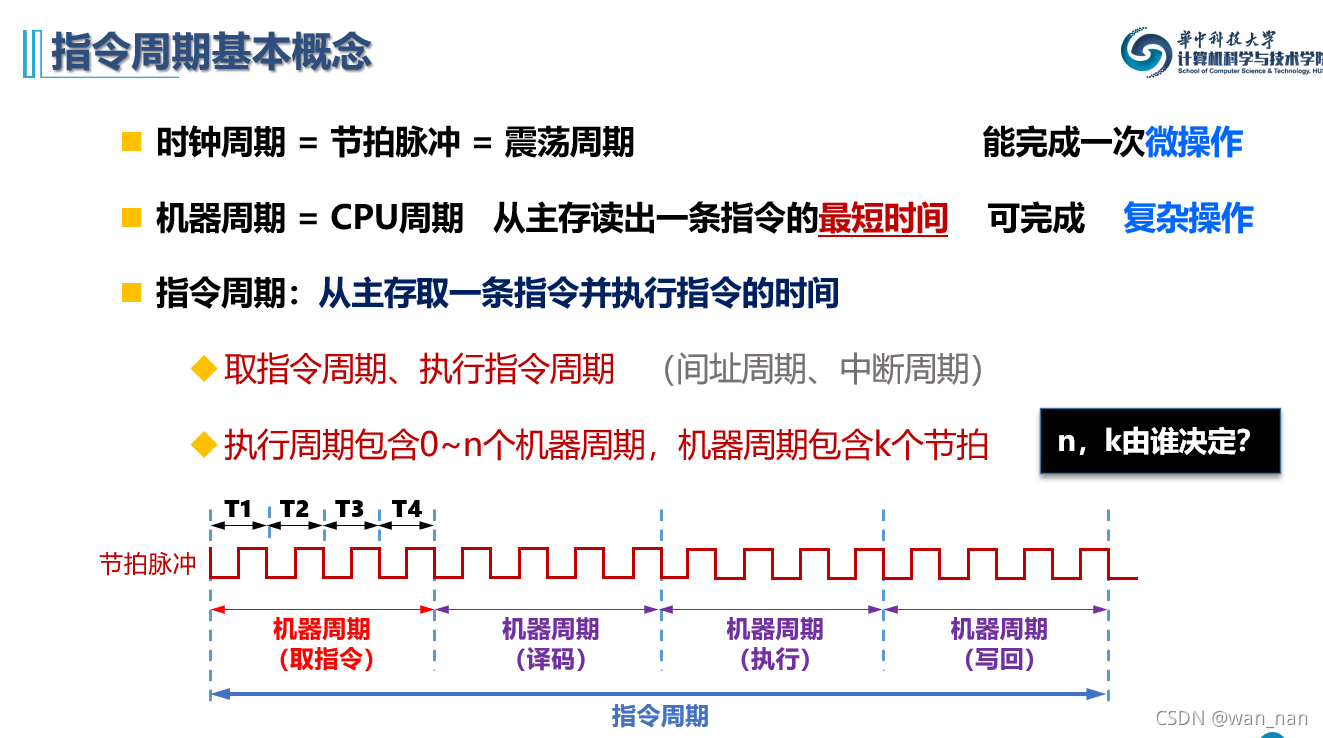
机器周期:从cache读出一条指令的最短时间,也就是说,取指令的时间刚好是一个机器周期
所有指令都是以cache命中为基础的
一般取指令包含一个机器周期,执行指令需要若干个机器周期
一个指令周期至少包含两个机器周期(取指令和执行指令),但MIPS最短只需要一个机器周期
n和k由设计者来决定,一个机器周期包含的节拍也不是固定的
指令周期同步
- 定长指令周期:早期三级时序系统
- 还有机器周期的概念
- 机器周期数固定,节拍数固定,按机器周期同步,如MIPS单周期
- 变长指令周期:现代时序系统
- 简单一点就是状态机,已经没有机器周期的概念
- 机器周期数可变,节拍数可变,按时钟周期同步,如MIPS多周期
- 定长指令周期只是变长指令周期的一个特例
- 定长指令周期:早期三级时序系统
数据通路:执行部件间传送信息的路径(数据流)
通路的建立由控制信号控制,受时钟驱动(控制流)
不同指令、同一指令在执行的不同阶段 数据通路不同
分类:共享通路(总线)、专用通路
以下两点有所不同
- 指令执行流程、执行效率
- 微操作控制信号的时序安排
抽象模型:

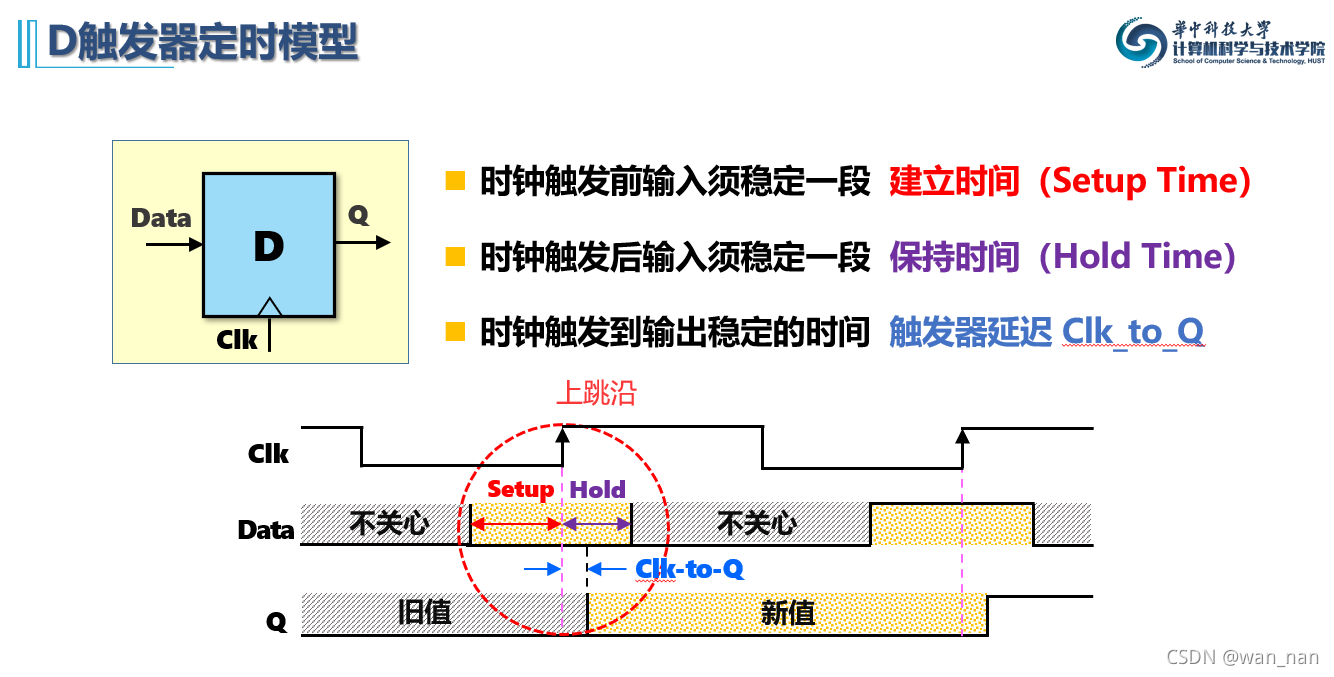
D触发器定时模型
寄存器可以看作多位的D触发器
所以数据通路中寄存器的时间延迟也必须遵守下图中的建立时间、保持时间和触发器延迟
数据通路与时钟周期
下图中的相关参数与上图中类似
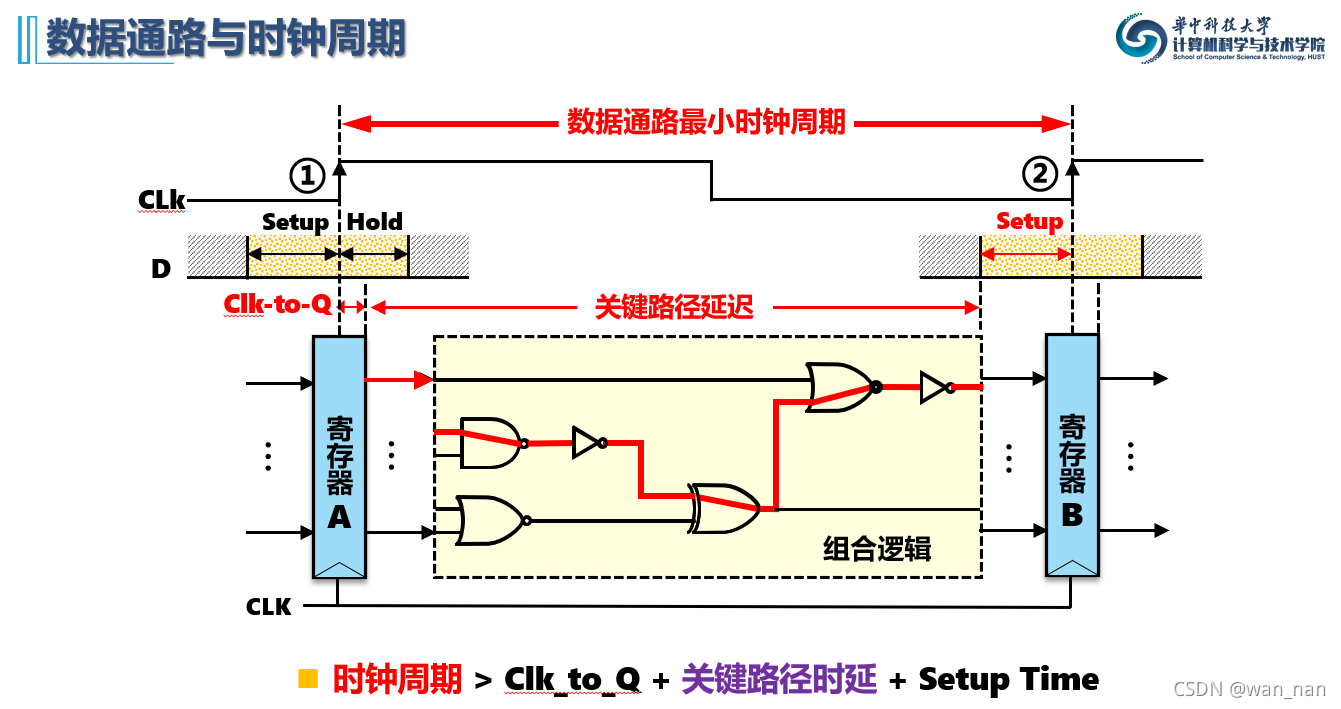
要提升CPU频率,要尽可能把上图中的关键路径延迟降低
保持时间违例
(保持时间要小于某个值,避免与真正的输入相重叠)
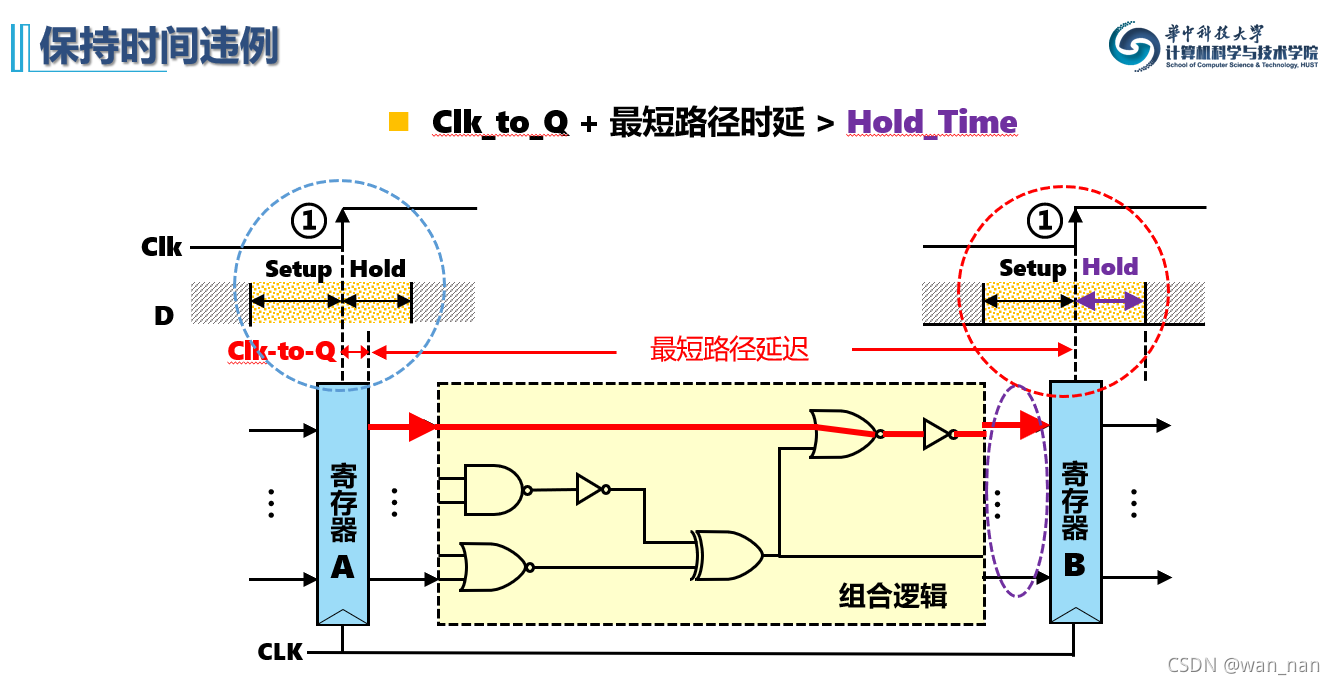
例题
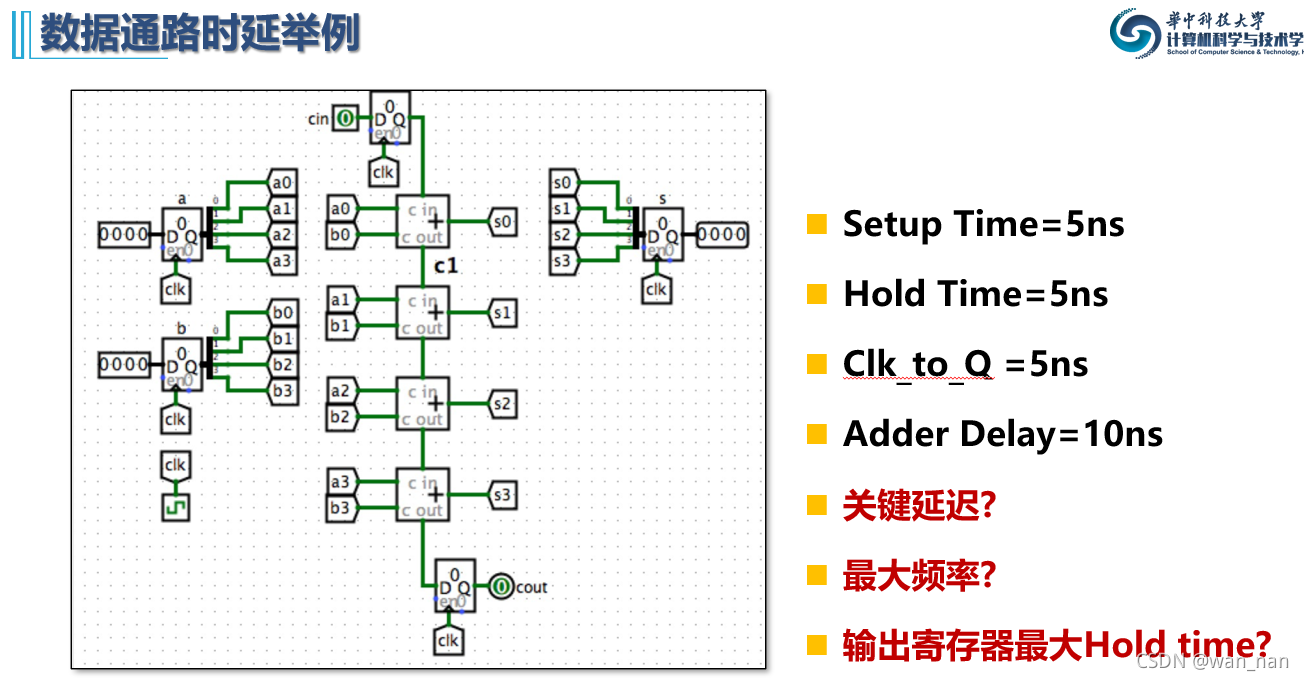
关键延迟:即在问关键路径上导致的延迟:4个加法器,为40ns
最大频率:即在问数据通路最小时钟周期的倒数
输出寄存器最大Hold time:即在问保持时间违例
数据通路分类
共享通路(总线型)
主要部件都连接在公共总线上,各部件间通过总线进行数据传输
结构简单,实现容易,但并发性较差,需分时使用总线,效率低
专用通路
并发度高,性能佳,设计复杂,成本高
可以看作多总线结构
CPU总线结构实例
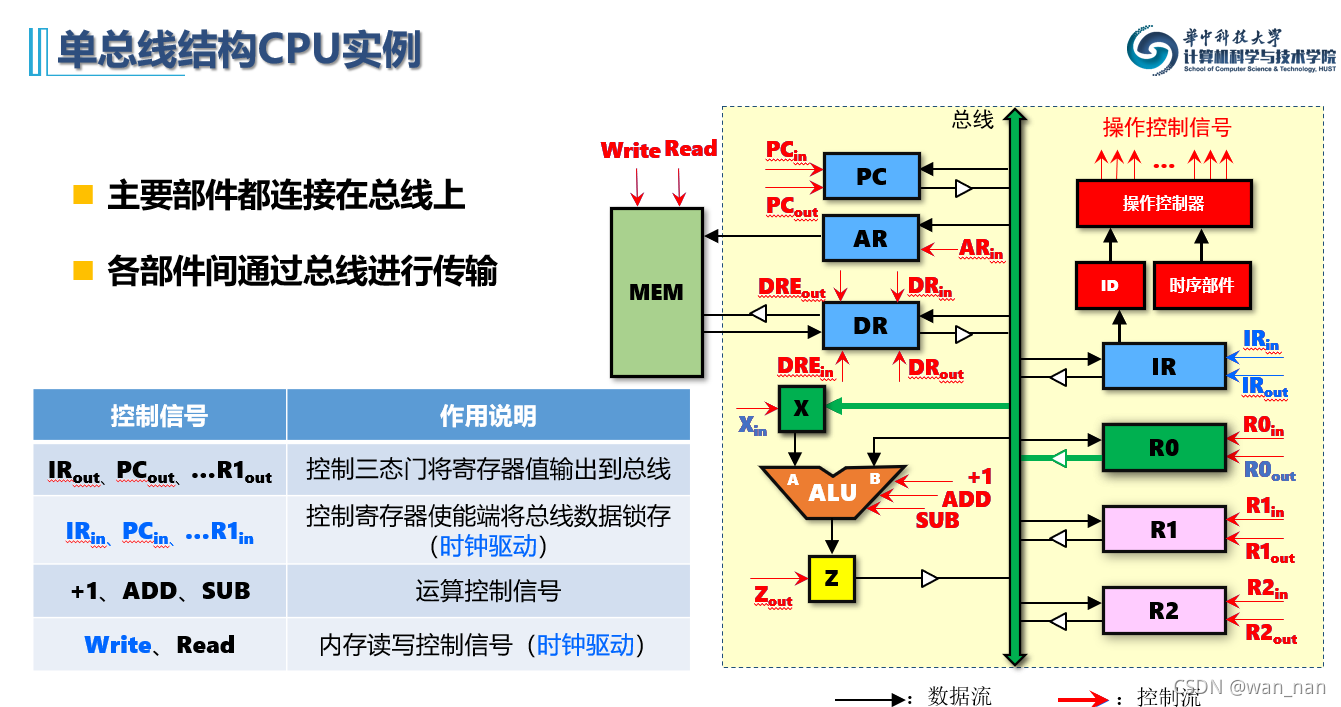


- 单总线结构下的MIPS还是需要程序状态寄存器的
指令周期
数据流:

控制流:
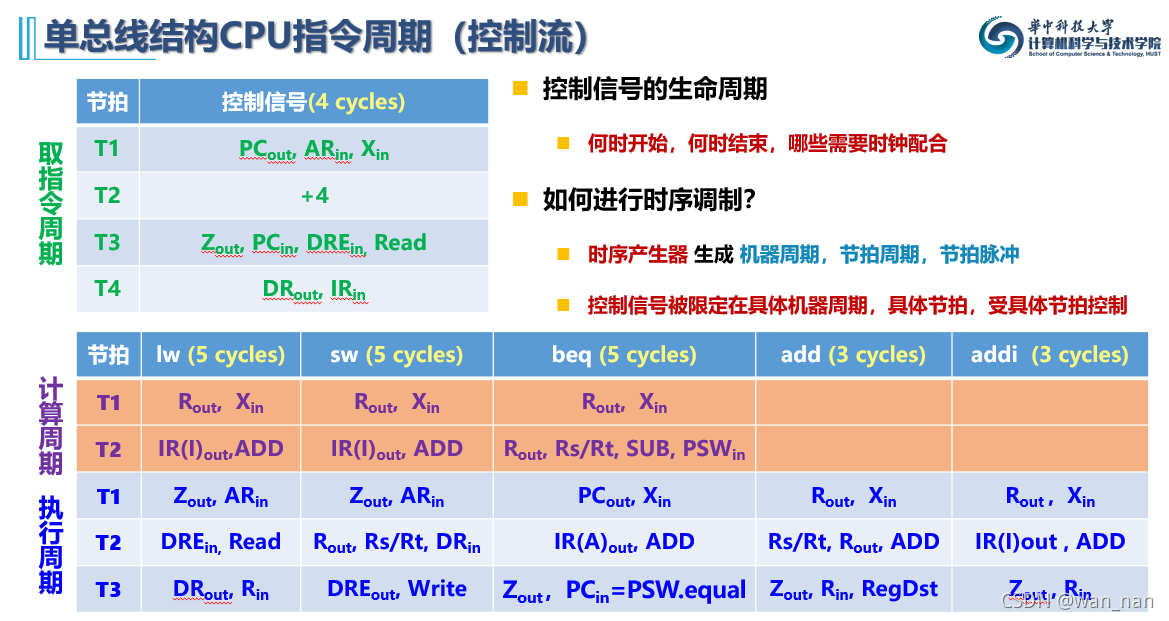
节拍脉冲的上跳沿用来锁存寄存器(如前文所述)
下跳沿则产生变化,改变信号,实现状态机的切换,机器周期之间的转换
- 本文链接:https://wan-nan.github.io/2021/09/20/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BB%84%E6%88%90%E5%8E%9F%E7%90%86/
- 版权声明:本博客所有文章除特别声明外,均默认采用 许可协议。