- 文书(个人陈述等等)
- 英语!!
一些注意事项
填写申请系统的时候“备注”栏千万不可以空缺
数学(线代>概率论>=离散>高数)== 数据结构>操作系统>计算机网络>程序设计语言(C++,JAVA,PYTHON)>数据库>计组>>思政>>>>其他
项目
- Cobb的深度学习部分 模型相关的代码 例如:使用了什么优化器
- 计网
- 贪吃蛇
CobbPredict
代码量(各个部分都要分开统计):接近4k行代码
后端:1281行(Python)

前端:2365行(Vue)+141(JavaScript)

网络怎么连通的(Frp)
部署
原理(文档):通过自定义域名访问内网的 Web 服务
操作(步骤):使用Frp内网穿透访问内网Web项目
前端
Vue+JavaScript+Axios+element-ui
后端
数据库部分
一共两张表,如下图所示:

- 一张表
Users,存储用户名和密码,主码是用户名 - 一张表
PatientImg,存储患者信息,主码是imgPath(因为考虑到同一个患者也可能多次使用平台,所以用路径作为主码,且表名也是“PatientImg”),username为外码reference username in Users- 图片放在本机服务器上,用字符串的方式在数据库中存储其路径
- 一张表
模型
ISBI2020
Our vertebra-focused(椎骨聚焦) landmark detection network is illustrated in Fig. 2. The inputs of the network are gray-scale images with size fixed to 1024×512. First, we use ResNet34 conv1-5 to extract the high-level semantic features(语义特征) of the input image. Then we use the skip connections to combine the deep features with the shallow ones to exploit(利用) both high-level semantic information and low-level fine details(细节), similar to [16, 17].
深度特征融合—理解add和concat之多层特征融合:add可以认为是特殊的concat形式。但是add的计算量要比concat的计算量小得多
“使用skip connection将深层特征与浅层特征结合起来,以利用高级语义信息和低级精细细节”
上采样采用的方式是bilinear interpolation双线性插值(用矩形边界点的值来计算矩形中任意一个点的值)
具体特征融合的方式可以看下图类比理解:

最后面就是三个卷积层来实现
At layer D2, we construct the heatmap, center offset and corner offset maps using convolutional layers for landmark localization.

D2层是256×128×64,经过卷积层调整channels的个数,经过卷积层得到三种输出
channels=1为
heatmap,1维的表示二维图像中的每个像素点是否(0/1)是椎骨中心channels=2为
Center Offset,2维的表示二维图像中中心点坐标的偏移 (dx,dy)【L1 loss】
channels=8为
Corner Offset,8维的表示每个椎骨的四个landmark的偏移 (dx,dy)【L1 loss】
网络结构:
base_network是resnet34dec_net即为上面的示意图中的后面的卷积层部分,包含上述三个部分
将骨干网络
base_network提取出的特征送入dec_net三个不同的卷积层网络中,进行上述三个结果的预测
有了这些预测结果,即可计算得到每块椎骨的landmark角点坐标
贪吃蛇
机试
C++中的文件输入输出:
freopen将输入输出重定向此后原本用于标准输入输出的
cin/scanf和cout/printf都会输出到文件中1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
using namespace std;
int main()
{
freopen("a+b.in","r",stdin);
freopen("a+b.out","w",stdout);
//以上是模板
int a,b;
cin>>a>>b;
cout<<a+b;
// 把标准输出stdout再重新定向回控制台,Windows中是"CON",Linux中是"/dev/console"
// freopen("CON", "w", stdout);
// cout<<"finish"<<endl;
return 0;
}
英语

Sorry,Can you pardon it again?
一张图(英语常见问答)见文末
Common expressions
- Data center network
- artificial intelligence
- doctor master undergraduate senior
- in advance
- MST:minimum spanning tree
- Greedy Algorithm
- Edges and Points
- Square of n / the second power of n
- Expand your horizons
- central idea
- good environment
- Complete graduation requirements
- refuse
- avoid
- original intention
- in order
- Recursive
- union-set
- ancestor
- amount
- Directed acyclic graph(DAG) acyclic(A-cyclic)
- do A while doing B / and
- repeat
- Mark v as the number of points in the graph
- from small to large
talk about the union-set
In the union-set, each node belongs to a set, and each set has a unique ancestor. We need a hash_ map to store the parent of each node, in which the key is node and the value is his parent.
Different with simple nodes, the ancestor of an ancestor node is itself. This is also the way to find ancestor nodes.
When we need to find the ancestor of a node, we find the parent of the node in the hash_map and perform this process recursively until the found parent is the node itself.
When we need to merge two sets, we only need to set the ancestor of one set as the parent of the other’s ancestor. This process is like merging two trees.
talk about the Topological sort
Directed acyclic graph(DAG)
in-degree
Delete them and update the in-degree of the other points.
The points we delete each time are in the same position in the ordered sequence.
Talk about your hometown.
I have the high privilege and sincere eagerness to present it to you, my beautiful hometown Sanmenxia.
It’s a delicate town located in the westernmost part of Henan Province, which is famous as the city of swans because numerous number of swans fly a long journey from Siberia over here every winter. We are quite confident that it is our agreeable natural environment that attracts these elegant creatures.
The reason why my hometown is called Sanmenxia is because Sanmenxia is based on the myth of Dayu cutting the mountain into three gorges, namely “Renmen”, “Shenmen” and “Guimen”, with his magic axe to lead the water of the Yellow River to the east. Hence the name of Sanmenxia.
Hangu pass is one of the historical sites here. It is said that Lao Tzu wrote the Tao Te Ching here.
Sanmenxia has profound historical culture and beautiful natural scenery. Welcome to my hometown and you bet I will treat you well.
Introduce yourself in English.
My name is Nan Haixin. I come from Huazhong University of Science and Technology. My major is Computer Science and Technology. My average grade is 90.74 (ninety point seven four), ranking about the top 3% (three percent) in my major.
I command a high level of proficiency in English. I got 473 (four hundred seventy-three) in CET-6.
In addition, I participated in the China robot and artificial intelligence competition and won the national first prize. And I participated in the Interdisciplinary Contest In Modeling in 2022 and was awarded as Meritorious Winner.
What’s more, I was awarded the title of “Scholarship for National Encouragement” for two consecutive years. And I own a computer software copyright, in which I am the second copyright owner.
Fudan university is always my dream school and I hope I can be admitted to Nanjing University.
Why do you choose our school?
The first and most important point, Nanjing university has great advantage in Computer science and Technology, both in the field of artificial intelligence and systems. What’s more, I love the inclusive atmosphere of Nanjing University.
The school motto of Fudan University, free and useless, attracts me very much. And I love the inclusive atmosphere of Fudan University. Fudan university is located in Shanghai, and I love this city, and I think it is the most charming city in China and it has many opportunities there.
Your strength and weakness?
I am very organized in my work. For example, I am used to listing the learning plan of the day in my notebook every day. At the end of the day, I will review what I did that day and do some self reflection and daily summary.
When I am busy, I will become impatient with others and put my own things first. This will cause me to often ignore the feelings of others when I am busy. Now, although I am busy, I will actively respond to others and explain to others that I am busy in exchange for others’ understanding.
What’s your plan after graduation?
It is hard to say, I am more inclined to work, and of course I also have plans to further study.
The reason for further studying?
I realize what I have learned during the past years is not enough for the future, it is necessary to catch any opportunity for self-development.
What’s your favorite course and why?
There is no doubt that my favorite course is Computer Network. In the process of learning this course, I learned a lot of Internet protocols and have a deeper understanding of the Internet we use every day. It is these protocols that have formed the stable and reliable internet.
And when I finished my computer network experiment, and the web page I made could be accessed by a browser under the same local area network, I was very satisfied.
机器学习
数据库
计网
编译原理
概率论
线性代数、离散数学
组原
数据结构
操作系统
数据结构
Q:有一个循环队列Q,里面的编号是0到n-1,头尾指针分别是f,p,现在求Q中元素的个数?
A:
(p-f+n)%n
Q:如何区分循环队列是队空还是队满?
A:如上,两种解决方式。牺牲一个单元则(Q.rear+1)%MaxSize == Q.front为队满,Q.rear == Q.front为队空;增设表示元素个数的数据成员则Q.rear == Q.front且Q.size == 0为队空,Q.rear == Q.front且Q.size == MaxSize为队满
Q:==堆、大顶堆、小顶堆的实现及应用==
A:堆是具有下列性质的完全二叉树:每个结点的值都大于或等于其左右孩子结点的值,称为大根堆;或者每个结点的值都小于或等于其左右孩子结点的值,称为小根堆。
耗费O(n)的复杂度建堆之后可以用O(logn)的复杂度维护一次堆
插入新的数只需要插在最后,再更新一次堆即可;
删去最小值or任意一个(第k个)数只需要将其与最后一个数交换,删去最后一个数,再更新第k个数即可
A:散列表是根据关键字而直接进行访问的数据结构。也就是说,散列表建立了关键字和存储地址之间的一种直接映射关系。
构造哈希函数:直接定址法、数字分析法、平方取中法、除留余数法、随机数法
解决哈希冲突:开放定址法、链地址法(拉链法)、公共溢出区法
Q:无向图or有向图判断是否有环
A:拓扑排序、并查集、DFS(链接)
无向图还可以通过“n个顶点,n-1条边”来确定
==BST→AVL→B树→B+树==
BST:二叉排序树
ACL:平衡二叉排序树
能确保AVL的查找、添加、删除的时间复杂度都是O(logn)
AVL树上任意结点的左、右子树的高度差最大为1
B树:平衡多路查找树
B树的所有叶子结点都位于同一层
其多路的性质帮助降低树的高度,减少查找次数
【B树不会有重复索引,每个结点都包含索引值和data两部分】
B+树
【B+树内部有两种结点,一种是索引结点,一种是叶子结点;可以理解为只有叶子结点有data】
B+树的叶子结点都会被连成一条链表。叶子本身按索引值的大小从小到大进行排序。即这条链表是 从小到大的。多了条链表方便范围查找数据
【B+树 非叶子结点的索引值 最终一定会全部出现在 叶子结点中】
几种排序
优先队列的原理:本质上还是基于堆的上浮下沉操作
绪论
时间复杂度:
一个语句的频度是指该语句在算法中被重复执行的次数。算法中所有语句的频度之和记为T(n), 它是该算法问题规模 n 的函数,时间复杂度主要分析T(n) 的数量级。
算法中基本运算(最深层循环内的语句)的频度与T(n) 同数量级,因此通常采用**算法中基本运算的频度f(n)**来分析算法的时间复杂度。
而O(n)中的大O表示上紧确界,用于描述$f(n)$的上界
O(n)的大O是什么意思?什么是时间复杂度?
数据结构的三要素:逻辑结构、存储结构(物理结构)和数据的运算
逻辑结构:指的是数据元素之间逻辑关系,与数的存储结构无关,是独立于计算机的,以下是分类图。
与存储结构之间的区别是,例如数组属于顺序存储,链表属于链式存储,但他们都属于线性结构

存储结构:
顺序存储:把逻辑上相邻的元素存储在物理位置上也相邻的存储单元中,元素之间的关系由存储单元的邻接关系来体现。
【优点】支持随机存取
【缺点】使用连续空间导致产生较多的碎片;插入删除需要移动元素
链式存储:不要求逻辑相邻的元素物理位置也相邻,借助指针来表示逻辑关系
【优点】充分利用存储空间,无碎片现象;且插入删除不需要移动其他元素
【缺点】指针占用额外存储空间,且只能顺序存取(无法随机存取)
索引存储:(与hash散列存储不同)要在索引表中查找索引项,进而得出地址,索引表一般存储(关键字,地址)
例如数据库中建立的索引
【优点】检索速度快
【缺点】使用索引表增加了额外的空间占用;增加和删除数据时也要修改索引表
散列存储:(又称hash存储)根据元素的关键字直接计算出该元素的存储地址
【优点】检索、增加和删除结点的操作都很快
【缺点】若散列函数不好,则可能出现元素存储单元的冲突,而解决冲突会增加时间和空间开销。
递归与迭代:
在循环的次数较大的时候,迭代的效率明显高于递归。
递归调用需要维护活动记录,而迭代直接复用了存储,可以省略这些开销,所以体系结构若执行显式递归调用一般更慢。但这里一般也不会慢多少,主要还是存储空间有压力(调用栈溢出)。
线性表
-
不太懂没有头结点的时候为什么头指针不能为空,那这个时候空链表的头指针不就是null吗
还是默认有头结点好了
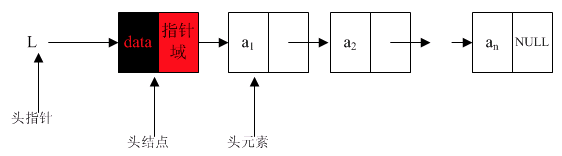
头指针
头指针是指链表指向第一个结点的指针,若链表有头结点,则是指向头结点的指针
头指针具有标识作用,所以头指针冠以链表的名字(指针变量的名字)
无论链表是否为空,头指针均不为空
ListNode dummy = new ListNode(0);这句创建出来的**dummy就是头指针**,有头指针才有链表,所以“无论链表是否为空,头指针均不为空”头指针是一个指针!并没有值域
头指针是链表的必要元素
头结点
- 头结点是为了操作的统一和方便而设立的,放在第一个元素的结点之前,其数据域一般无意义(但也可以用来存放链表的长度)
- 有了头结点,对在第一元素结点前插入结点和删除第一结点起操作与其它结点的操作就统一了
- 头结点不一定是链表的必要元素
栈和队列
共享栈:

栈和队列都可以用定长数组模拟,而循环队列也是用定长数组模拟队列,普通的模拟队列没有循环的特性
对于循环队列:判断队列空和满【队头指针指向第一个数;队尾指针指向最后一个数的下一个位置,即将要入队的位置】

【栈的用途】括号匹配、计算后缀表达式、递归
【队列的用途】树的层序遍历、任务处理的等待队列
串
子串的定位称为模式匹配
KMP:匹配过程的时间复杂度为O (n),计算next数组的时间复杂度为O (m),共O(m+n)
主串—子串(模式串)
在KMP算法中,(记i为主串中的下标,j为子串中的下标)i不会回溯,只用在主串中遍历一遍。
【KMP流程】遇到不匹配的情况,i保持不变,j移动到
next[j]处,继续匹配。【KMP本质】所以KMP是空间换时间的方法,需要预处理的只有模式串(子串),计算子串的
next数组。【
next[j]含义】next[j]存的是子串【从j往前数的后缀(不包含j)】与【从0往后数的前缀】最大重合的长度【特殊处理】
next[0] = -1,表示上来第一个就不一样,这时只能i++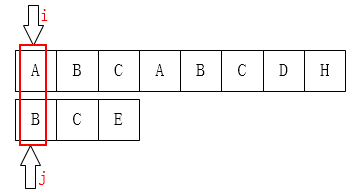
【
next数组求法】:一共j和k两个下标
当
P[k] == P[j]时, 有next[j+1] == next[j] + 1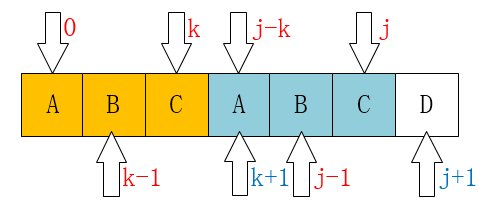
当
P[k] != P[j]时,有k = next[k]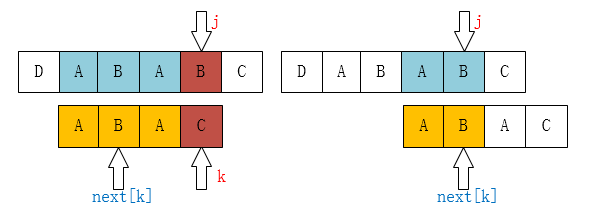
上边的例子,我们已经不可能找到[ A,B,A,B ]这个最长的后缀串了,但我们还是可能找到[ A,B ]、[ B ]这样的前缀串的。所以这个过程像不像在定位[ A,B,A,C ]这个串,当C和主串不一样了(也就是k位置不一样了),那当然是把指针移动到next[k]啦。
核心代码:
1
2
3
4
5
6
7
8
9
10next[0] = -1;
int j = 0;
int k = -1;
while (j < p.length - 1) {
if (k == -1 || p[j] == p[k]) {
next[++j] = ++k;
} else {
k = next[k];
}
}
树与二叉树
图
见我的另一篇数据结构-图-总结
查找
这章没看,摆了
删除二叉排序树中某个有两个孩子的结点时,需要查找中序遍历中该元素的直接后继来代替
排序
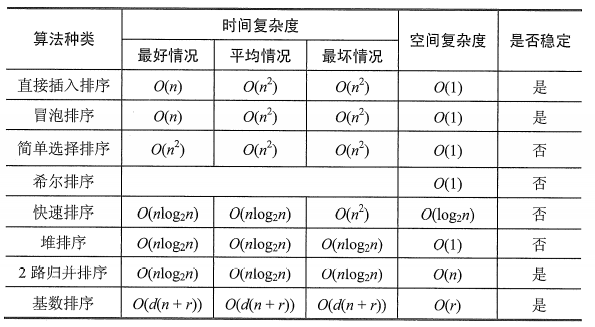
几种排序算法这里都有介绍
O(n)的时间复杂度求无序序列中位数【使用快排中的Partition()操作】
选择排序和插入排序:
插入排序一定是比选择排序更优的,1.最好情况插入排序的时间复杂度更低;2.插入排序是在线算法,选择排序是离线算法。即插入排序支持处理数据流。
概率论
古典概型:优先等可能
几何概型:无线等可能(如正方形中圆形的概率)
大数定律:
当样本数据无限大时,样本均值趋于总体均值(期望值)。
When the sample data is infinite, the sample mean tends to the overall mean.
大数定律告诉我们能用频率近似代替概率;能用样本均值近似代替总体均值。
中心极限定理:样本数量无穷大的时候,样本均值的分布呈现正态分布
中心极限定理指的是给定一个任意分布的总体。我每次从这些总体中随机抽取 n 个抽样,一共抽 m 次。 然后把这 m 组抽样分别求出平均值。 这些平均值的分布接近正态分布。
- 总体本身的分布不要求正态分布
对于人的体重等例子,其总体原本就满足正态分布。但如果我们的例子是掷一个骰子(离散型随机变量),最后每组的平均值也会组成一个正态分布。(神奇!)
- 总体本身的分布不要求正态分布
正态分布:
正态分布描述的是一种【连续型随机变量】的分布。对于这种变量,我们不关注点概率,只关注区间概率
正态分布的曲线是其概率密度函数,与横轴的面积为该区间的概率
两个相互独立的正态分布之和仍然符合正态分布

两个相互独立的正态分布的乘积等价于正态分布的概率密度函数乘一个常数,即积分过后得到一个不等于1的常数

全概率公式和贝叶斯公式
全概率公式:
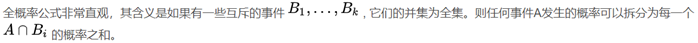

贝叶斯公式:(本质是条件概率公式,但实际上还是两个东西)
其作用是:基于已知的【先验概率和条件概率】求后验概率

理解先验概率和后验概率:
先验概率:事情未发生,只根据以往数据统计,分析事情发生的可能性,即先验概率。
后验概率:事情已发生,已有结果,求引起这事发生的因素的可能性,由果求因,即后验概率。
感冒、中风、脑溢血导致头痛的概率为先验概率
现在有一个病人头痛,其感冒的概率则为后验概率
全概率公式由因求果,其中的概率即为先验概率
后验概率的计算需要借助先验概率,使用贝叶斯公式,由果推因
理解互斥和独立

不相关和独立的区别:
不相关说的是:两个变量的相关系数为0,两个变量之间没有线性关系
独立说的是:P(AB)=P(A)×P(B),事件 A 发生的概率不影响事件 B 发生的概率
所以有:
- 独立一定不相关
- 不相关不一定独立(可能不是线性关系,但有其他关系,导致P(AB)≠P(A)×P(B))
-
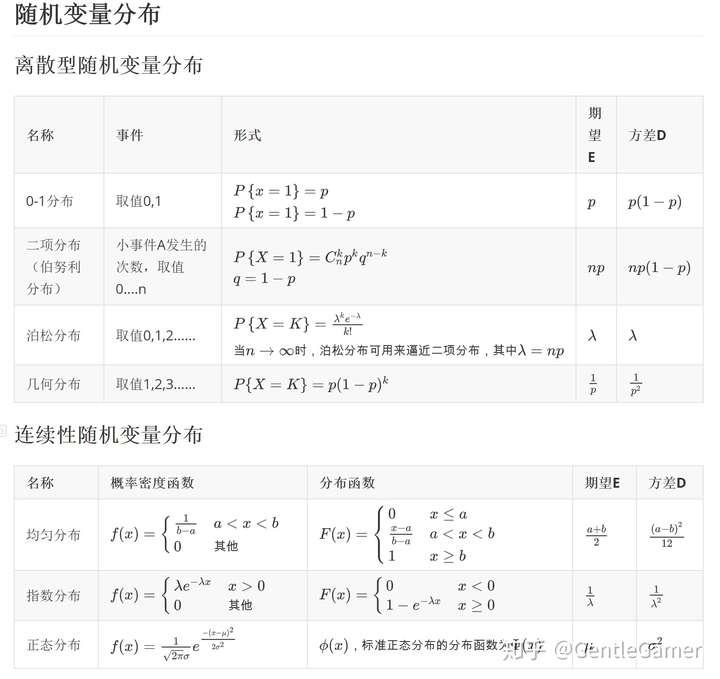
期望和方差:$D(X)=E((X−E(X))^2)=E(X^2)−E^2(X) $(期望 = 平方的期望 - 期望的平方)
协方差—相关系数
协方差or相关系数=0 => 不线性相关(不能说明独立or无关)

假设检验的例子:

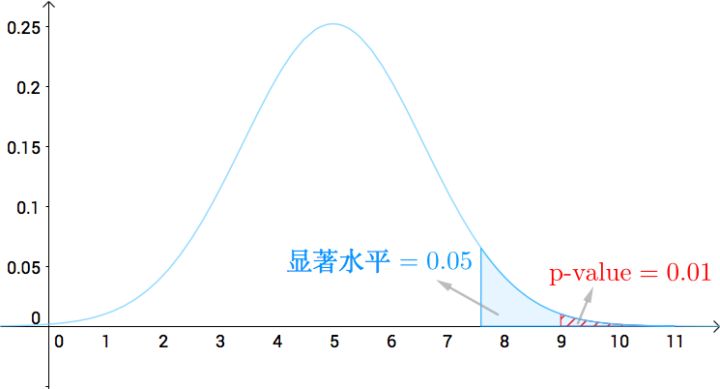
假设:我的硬币公平,则按照这个假设计算出“10次掷出9次正面”的概率为0.01,小于显著水平0.05,可以认定为不可能事件,所以假设不正确
概率(probability)和似然(likelihood)的区别

最大似然估计:
利用已知的样本结果信息,反推最具有可能(最大概率)导致这些样本结果出现的模型参数值
解题步骤
- 写出总体分布概率密度函数
- 写出似然函数
- 求似然函数的最大值(取对数后,求导,令其等于0)求解估计的参数
-
马尔可夫链就是这样一个任性的过程,它将来的状态分布只取决于现在,跟过去无关!这就是马尔科夫过程(Markov Processes)的体现,
问题集锦:
夫妇生孩:

大数定律玩骰子:

罐子抽球“最大似然”:

线性规划:

抛硬币吃苹果:

均分扑克牌后大小王在一起:(大小王被分配这两个事件并不独立,所以要列出所有可能性进行计算)

机器学习
组原
看的这个:计算机组成原理保研面试题整理(自用)
总线:总线是连接各个部件的信息传输线,使各个部件共享的传输介质
总线分为内部总线、系统总线和通信总线。内部总线指芯片内部连接各元件的总线。系统总线指连接计算机各部件的总线。外部总线则是计算机系统之间或计算机系统与其他系统之间的通信。
其中,系统总线又分为三类,数据总线,地址总线和控制总线
引入总线的目的:
在冯诺依曼结构中,各个部件之间均有单独连线,不仅线多,而且导致扩展I/O设备很不容易。即扩展一个I/O设备,需要连接很多线。 因此,引入了总线连接方式,将多个设备连接在同一组总线上,构成设备之间的公共传输通道。
总线的两大特征:
1)共享:多个部件连接在同一组总线上,各个部件之间都通过该总线进行数据交换。
2)分时:同一时刻,总线上只能传输一个部件发送的信息;
数据校验:增加冗余码(校验位)
- 奇偶校验(不具备纠错能力)
- CRC循环冗余校验
- 海明校验
存储系统层次结构:
缓存-主存:缓解CPU和主存速度不匹配的问题,由硬件来完成
主存-辅存:解决主存容量不够的问题,由操作系统和硬件共同完成
存储方式:大端-小端(回想学汇编时栈的存储,即为小端方式)
- 大端:字的低位存在内存的高地址中,而字的高位存在内存的低地址中;
- 小端:字的低位存在内存的低地址中,而字的高位存在内存的高地址中;
存储器的扩展通常有位扩展和字扩展
1)位扩展:增加存储器的字长,例如两个1K * 4位的存储芯片构成1个1K*8位的存储器;
2)字扩展:增加存储器的字数,例如两个1K * 8位的存储芯片构成1个2K * 8位的存储器;
在CPU和内存之间引入cache的原因
1)避免CPU空等I/O访存;
2)缓解CPU和主存速度不匹配的问题。
Cache写操作有哪两种方式
1)写直达法:写操作既写入Cache又写入主存;
2)写回法:只把数据写入Cache而不写入主存,直到Cache的该数据块将被驱逐出缓存时才写入主存。
Cache与主存的地址映射方式:
直接相联
全相联
组相联:主存和Cache都分组,主存中一个组内的块数与Cache中的分组数相同,组间采用直接映射,组内采用全相联映射。
Cache替换算法:
先进先出法-FIFO(First in First out)
最不经常使用法—LFU (Least Frequently Used)
近期最少使用法—LRU(Least recently used )
TLB:(Translation Lookaside Buffer)
什么是TLB:
简单地说,TLB就是页表的Cache,其中存储了当前最可能被访问到的页表项,其内容是部分页表项的一个副本。只有在TLB无法完成地址翻译任务时,才会到内存中查询页表,这样就减少了页表查询导致的处理器性能下降。
为什么需要TLB
虚实地址转换时需要访问主存中的页表,访问主存是很耗时的,因为cache的高速特性得不到发挥
缺页-找到的页不在主存中-缺页异常处理程序-将存放在辅存中的调入到主存中
调入后,要重新走一边查找的流程,重新查找一次页号
中断服务程序的基本流程:
1)保护现场 2)中断服务 3)恢复现场 4)中断返回
DMA:
DMA,全称Direct Memory Access,即直接存储器访问,指外部设备不通过CPU而直接与系统内存交换数据的接口技术。
但是采用中断传送有它的缺点,对于一个高速I/O设备,以及批量交换数据的情况,只能采用DMA方式,才能解决效率和速度问题。DMA在外设与内存间直接进行数据交换,而不通过CPU,这样数据传送的速度就取决于存储器和外设的工作速度。
通常系统的总线是由CPU管理的。在DMA方式时,就希望CPU把这些总线让出来,即CPU连到这些总线上的线处于第三态–高阻状态,而由DMA控制器接管,控制传送的字节数,判断DMA是否结束,以及发出DMA结束信号。DMA与中断对比:
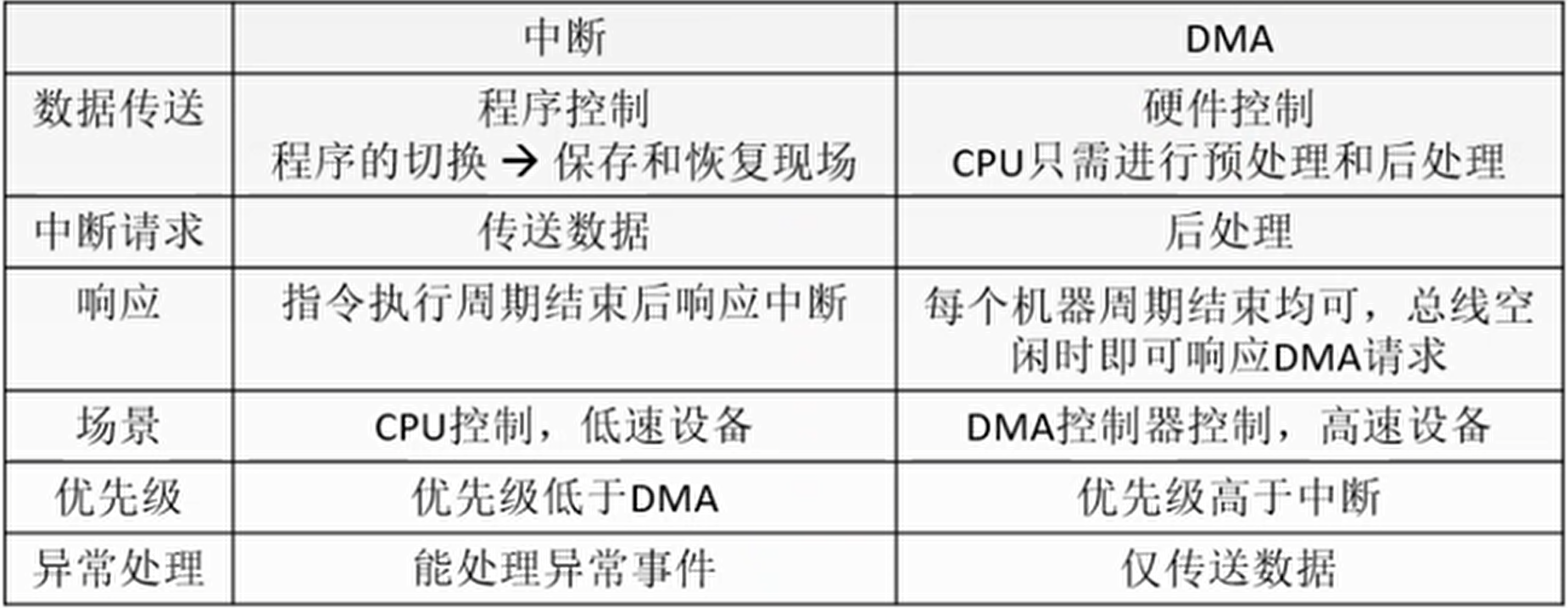
程序中断和调用子程序的区别:
两者的根本区别主要表现在服务时间和服务对象上不一样。
调用子程序过程发生的时间是已知的和固定的。而中断过程发生的时间一般是随机的。也可以说,调用子程序是程序设计者事先安排的,而执行中断服务程序是由系统工作环境随机决定的。
子程序完全为主程序服务,两者属于主从关系。而中断服务程序与主程序二者一般是无关的,两者是平行关系。
主程序调用子程序的过程完全属于软件处理过程,不需要专门的硬件电路;而中断处理系统是一个软/硬件结合的系统,需要专门的硬件电路才能完成中断处理的过程。
子程序嵌套可实现若干级,嵌套的最多级数受计算机内存开辟的堆栈大小限制;而中断嵌套级数主要由中断优先级来决定,一般优先级数不会很大。
五级流水CPU的各阶段:
取指(IF)
译码(ID,同时取出操作数)
执行(EX)
访存(访问存储器,MEM)
写回(数据写回到目标寄存器,WB)
流水线的冲突相关可以看系统结构的复习笔记
影响流水线性能的因素
结构相关是当多条指令同一时刻争用同一资源形成冲突
解决方案:(1)暂停一个时钟周期(2)单独设置数据存储器和指令存储器
数据相关是指令在流水线中重叠执行时,当后继指令需要用到前面指令的执行结果时发生的冲突
解决方案:(1)暂停一个时钟周期(2)数据旁路:把前一条指令的ALU计算结果直接输入到下一条指令
控制相关是当流水线遇到分支指令和其他改变PC值的指令时引起的.
解决方案:
(1)延迟转移技术。将转移指令与其前面的与转移指令无关的一条或几条指令对换位置,让成功转移总是在紧跟的指令被执行之后发生,从而使预取的指令不作废。
(2)转移预测技术。(动态分支预测)
计网
IP地址相关:(也可以帮助理解Frp的原理)
- 本机ipconfig查到的IP地址:(这个实际上是内网IP)

- 百度“IP地址”查到的地址:(这个是公网IP)
<img src="冲!/image-20220718205727962.png" alt="image-20220718205727962" style="zoom:67%;" />
- 本机ipconfig查到的IP地址:(这个实际上是内网IP)
网络边缘、网络核心和接入网络
网络边缘是指
主机or网络应用网络核心是指
互联的路由器or分组的转发设备接入网络:有线或无线通信链路
路由器的关键功能:路由+转发
报文交换-分组交换-电路交换
报文交换不存在多路复用,是将数据整个进行传输
比较落后
分组交换是在报文交换的基础上对数据进行分组传输,为统计多路复用(按需共享链路)
适合突发数据传输(不需要花时间像电路交换那样建立链路)
分组交换的报文交付时间公式:一个分组走h-1跳+所有报文走1跳
电路交换:建立连接,通信,释放连接
例如电话网络
Q:判断:电路交换网络中,每条电路独占其经过的物理链路。
A:×
Q:判断:电路交换更适合实时数据流传输。
A:√
电路交换中也有几种多路复用技术:
- 频分多路复用(电视)
- 时分多路复用
- 波分多路复用
- 码分多路复用
速率-带宽-延迟-时延带宽积
一般讨论的都是传输延迟,即关于数据大小(bits/B)和传输速率/带宽(bps)的延迟
高速网络链路提高的也是数据的传输速率
而传播速率的单位是(m/s)
时延带宽积(单位bits):**传播*时延带宽
也成为以比特为单位的链路长度
五层参考模型

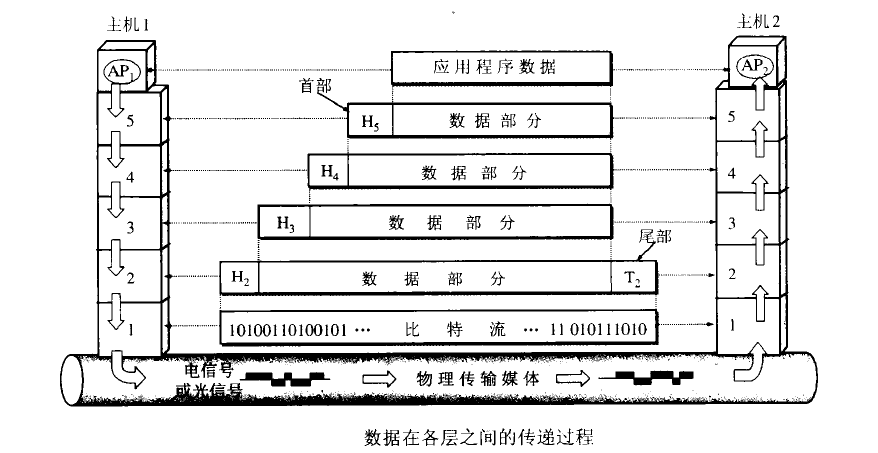
应用层
HTTP、SMTP、DNS
套接字socket
Socket是应用层与TCP/IP协议族(传输层)通信的中间软件抽象层,它是一组接口。在设计模式中,Socket其实就是一个门面模式,它把复杂的TCP/IP协议族隐藏在Socket接口后面,对用户来说,一组简单的接口就是全部,让Socket去组织数据,以符合指定的协议。(协助运输层复用/分解的实现)
如何编写socket套接字

UDP套接字由二元组:(目的ip,目的端口号)来标识,但UDP报文段仍包含了源ip和源端口号,可以在接收端获取
TCP套接字由四元组:(源ip,源端口号,目的ip,目的端口号)来标识
寻址进程
端口号是一个16bits的数,范围是0 ~ 65535;0 ~ 1023之间的端口号称为周知端口号

HTTP

TCP是有状态协议
HTTP是无状态协议
即HTTP的每个请求都是完全独立的,每个请求包含了处理这个请求所需的完整的数据,发送请求不涉及到状态变更。即使在 HTTP/1.1 上,同一个连接允许传输多个 HTTP 请求的情况下,如果第一个请求出错了,后面的请求一般也能够继续处理
非持久性连接 -> 无流水的持久性连接 -> 带有流水机制的持久性连接
(区分持久性连接和无状态协议)
HTTP报文是ASCII编码,人直接可读
SMTP
SMTP是有状态协议
常见的许多七层协议实际上是有状态的,例如 SMTP 协议,它的第一条消息必须是 HELO,用来握手,在 HELO 发送之前其他任何命令都是不能发送的;接下来一般要进行 AUTH 阶段,用来验证用户名和密码;接下来可以发送邮件数据;最后,通过 QUIT 命令退出。可以看到,在整个传输层上,通信的双方是必须要时刻记住当前连接的状态的,因为不同的状态下能接受的命令是不同的;另外,之前的命令传输的某些数据也必须要记住,可能会对后面的命令产生影响。这种就叫做有状态的协议。
使用TCP进行email信息的可靠传输
端口25
-
- 两者都是持久性连接
- HTTP是拉式,SMTP是推式
- SMTP要求每个报文使用7比特ASCII码格式(即七位的ASCII 码,ASCII码的取值范围是0~127)
- 对于既包含文本又包含图形(也可能是其他媒体类型)的文档,HTTP把每个对象封装在独立的响应消息中,而SMTP则把所有消息对象放在一个报文之中
POP3协议是无状态的
POP是负责邮件程序和邮件服务器收信的通讯协定,SMTP则是负责邮件服务器与邮件服务器之间的寄信的通讯协定
163、QQ Mail等邮箱都是基于HTTP协议的
DNS
Domain Name System 域名解析系统:域名→IP地址
先浏览器缓存 查询 是否之前已经解析过一次
系统缓存
路由器缓存
本地域名服务器
根域名服务器
顶级域名服务器
极限域名服务器
传输层
主要是TCP和UDP,这部分看书学习
-
复用和分解:区分不同进程的数据并且加以区分处理
可靠数据传输:(为了弥补网络层的不足)流量控制、拥塞控制、差错检测等等
运输层协议只工作在端系统中,在端系统中,运输层协议将来自应用层的报文移动到网络边缘(即网络层),但对这些报文在网络核心如何移动并不做任何规定
UDP和TCP的服务模型:
传输层提供的两种最低限度的服务(也即UDP提供的服务):进程到进程的数据交付(复用和分解)和少量的差错检查
但UDP和IP服务一样,都不可靠
TCP提供了附加服务:
【**可靠数据传输**】——通过使用流量控制、序号、确认和定时器,TCP确保将数据正确地、按序地从发送进程交付给接收进程,从而将端系统间不可靠的IP服务转换成了进程间的可靠数据传输服务
【拥塞控制】——TCP力求为每一个通过一条拥塞网络链路的连接平等地共享网络链路带宽,这可以通过调节TCP连接的发送端发送进网络的流量速率来做到(“一种带来通用好处的服务”)。而UDP的流量不可调节,使用UDP的应用程序可以根据其需要以任何速率发送数据
UDP相对于TCP的优势:
- 【可靠交付耗时】:TCP拥塞控制等确保可靠交付的操作会导致耗时增加,于是一些能容忍部分数据丢失的实时应用会使用UDP
- 【建立连接耗时】:TCP会引入建立连接的时延,DNS等服务为了加快速度选择使用TCP
- 【连接状态的维护】:TCP需要在端系统中维护连接状态,包括接收缓存、发送缓存和拥塞控制等的一些参数,选择运行在UDP上能比运行在TCP上支持更多活跃用户
- 【报文段开销】:TCP首部20字节,UDP首部8字节
可靠数据传输协议发展:rdt->(引入流水线)GBN滑动窗口协议->SR选择重传协议->TCP
GBN和SR

TCP
重传时机:收到3个冗余ACK(一个初始+三个冗余共四个相同的ACK)快速重传or计时器超时——都只重传base处的报文段(因此也只有一个计时器)
接收方:累计确认,ACK(n)表示n以前的全部确认
流量控制和拥塞控制:

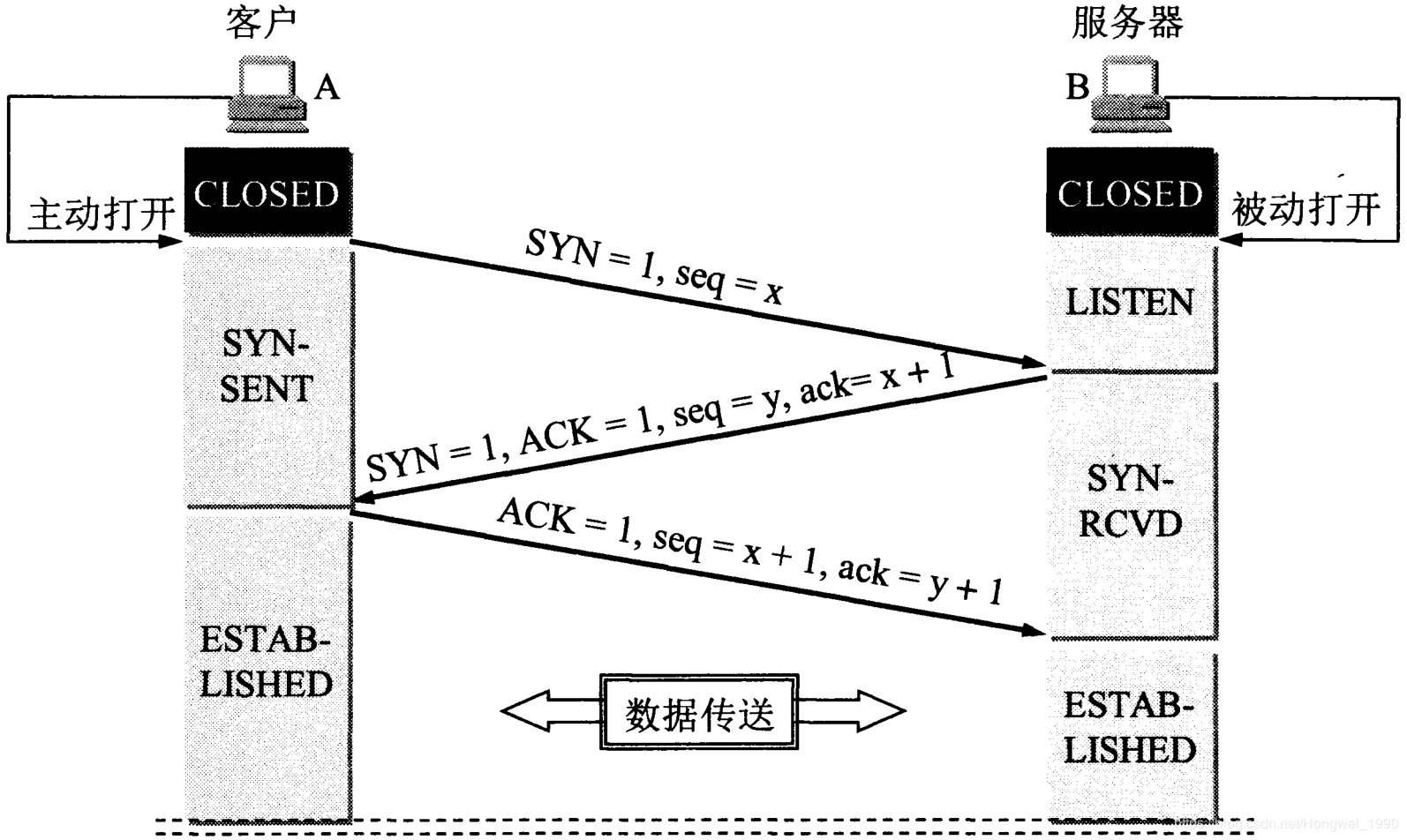
三次握手与四次挥手:
建立连接三次握手:
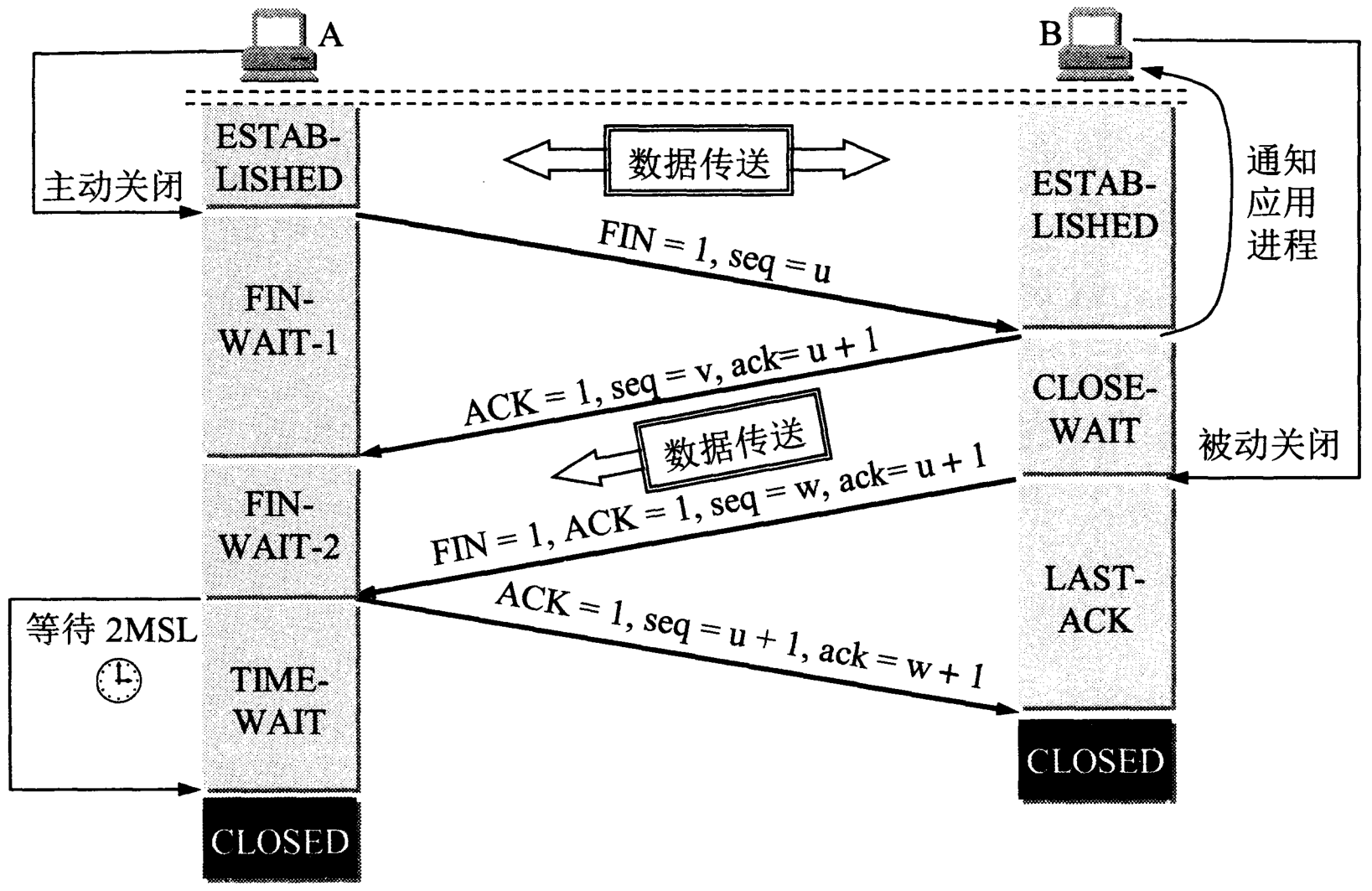
关闭连接四次挥手:
网络层
- 网络层服务:转发和路由
- 虚电路网络和数据报网络
- IP协议
- IP地址
- 共分为ABCDE五类,但只有ABC分为网络号和主机号
- 全0和全1一般不能用
- 私有IP地址:

- ICMP协议(互联网控制报文协议)
- IP地址
- 路由协议:RIP、OSPF、BGP
数据链路层
数据链路层提供的服务:

MAC多路访问控制协议:决定结点如何共享信道,即决策结点何时可以传输数据

MAC地址
IP地址(IPv4:32位;IPv6:128位),MAC地址(48位)
MAC地址固化在网卡的ROM中

ARP协议(Address Resolution Protocol):将已知IP地址转换为MAC地址
【是跨越链路层和网络层边界的协议】
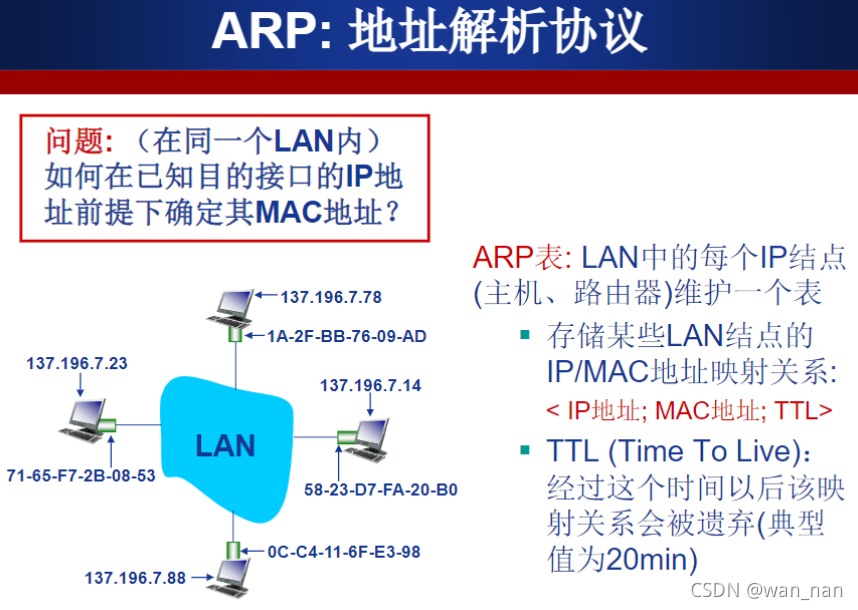

关于ARP寻址和MAC地址存在必要性的问题
IP地址更像用来 源 和 目的 之间端到端寻址,整个过程几乎不改变,少数改变的情况:从内网出去NAT可能要改变源IP地址
而MAC地址:在不断地经过路由器转发的过程中,被用来表示下一个阶段性目标,在到达目的主机之前,每走一段路转发一次,就需要更改
问题
Q:能不能直接在应用层把数据交给网络层?
A:在应用层直接把数据交给网络层,等于失去了复用分用功能,不会在ip数据报前面封装目的端口号,在分用的时候就不知道该将报文交付给哪个应用进程。除非在应用层完成原本在运输层应该完成的任务。

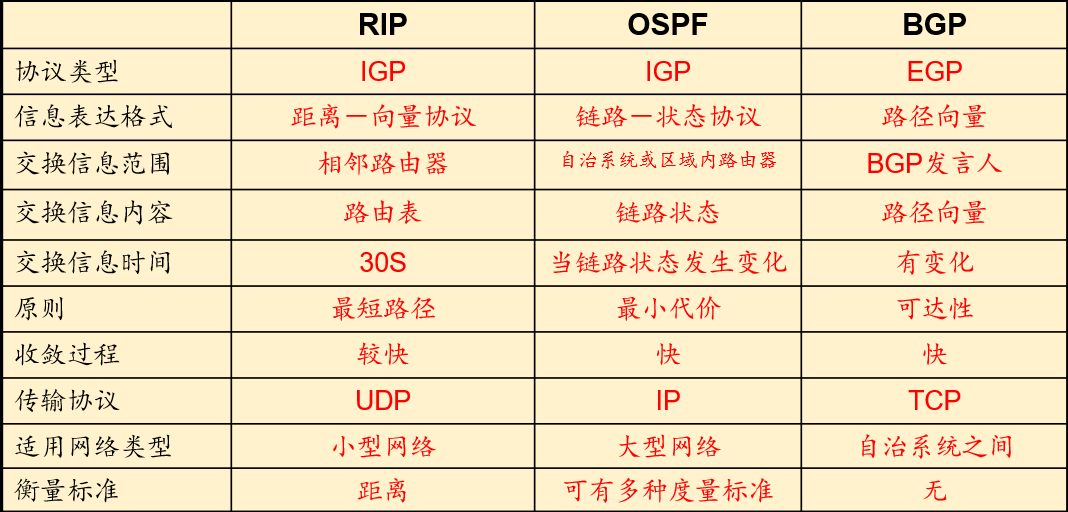
Q:RIP协议与OSPF协议?BGP协议?
自治系统或自治域(英文:Autonomous system, AS)
A:(RIP协议与OSPF协议两者都是AS内部网关协议)RIP协议如同他的名字,由于各方面的缺点(如无穷级数问题导致的最多15跳)已经不被使用,更多使用的是OSPF协议。RIP基于Floyd算法,OSPF基于Dijkstra算法。
- 两者区别
- RIP:每隔30秒,路由器将自己知道的全部信息,即整个路由表发送给相邻的路由器。
- OSPF:使用洪泛法向本自治系统的其他所有路由器发送信息
BGP:边界网关协议(属于外部网关协议)
应用层:HTTP、DNS、SMTP、RIP、BGP
传输层:TCP、UDP、OSPF(基于IP)
网络层:IP、ARP、ICMP
Q:域名解析过程:
A:
Q:Web页面请求历程
DNS映射:域名-IP地址
ARP映射:IP地址-MAC地址
上述两个映射都有缓存
Q:HTTP与HTTPS的区别
A:


数据库
ACID特性
ACID,是指数据库管理系统(DBMS)在写入或更新资料的过程中,为保证事务(transaction)是正确可靠的,所必须具备的四个特性:原子性(atomicity,或称不可分割性)、一致性(consistency)、隔离性(isolation,又称独立性)、持久性(durability)。

在数据库系统中,一个事务是指:由一系列数据库操作组成的一个完整的逻辑过程。例如银行转帐,从原账户扣除金额,以及向目标账户添加金额,这两个数据库操作的总和,构成一个完整的逻辑过程,不可拆分。这个过程被称为一个事务,具有ACID特性。
概念模型:E-R模型
逻辑模型:层次模型、网状模型、关系模型(基于此的数据库也成为关系数据库)
三级模式与两级映象
三级模式:


两级映象:

ER模型转换为关系模式:

数据库范式:
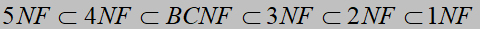
1NF:属性不可分
2NF:满足1NF,每个非主属性必须完全函数依赖于任何一个候选码(不存在非主属性对候选码的部分函数依赖,即不能只依赖于候选码的一部分)
3NF:满足2NF,不存在非主属性对候选码的传递函数依赖
BCNF:满足3NF,每一个非平凡函数依赖左部一定包含一个候选码(候选码可以由多个主属性组成)
4NF不提了
视图:(对应三级模式中的外模式)
视图是虚拟表,本身不存储数据,而是按照指定的方式进行查询。
当对通过视图看到的数据进行修改时,相应的基本表的数据也要发生变化。同时,若基本表的数据发生变化,则这种变化也可以自动地反映到视图中。
关系模式和关系:
“关系模式”和“关系”的区别,类似于面向对象程序设计中”类“与”对象“的区别。
”关系“是”关系模式“的一个实例,你可以把”关系”理解为一张带数据的表,而“关系模式”是这张数据表的表结构
关系模式是静态的,关系是动态的
- 关系模式是二维表的表头属性等,即一个二维表的主要架构。由于二维表的属性名一般不会修改,所以呈现出静态。
- 关系是一张二维表的具体数据,除去表头外各数据间的联系。由于二维表中是数据会时常修改,所以呈现出动态。
数据库增删改查
创建表:create
删除表:drop(删除某个列或某个约束时要结合alter使用)
约束:
constraint PK_student PRIMARY KEY(sno, cno),修改表结构:
```SQL
ALTER TABLE table_name
ADD column_name datatype
/DROP COLUMN column_name
/ALTER COLUMN column_name datatype1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
查询:select ··· from ··· where
- join/in
- group by
- having
- exists
表内容
- 增:insert into
```SQL
Insert Into <表名>[(<属性列>[{,<属性列>}])]
Values(<值>[{,<值>}])
Insert Into Student
Values (‘95020’, ‘陈冬’, ‘IS’, 18)删:delete from ··· where
1
2
3
4Delete From <表名>
[Where <条件>]
Delete From Student
Where Sno=‘95019’改:update ··· set ··· where
1
2
3UPDATE table_name
SET column1 = value1, column2 = value2...., columnN = valueN
WHERE [condition];
关系的完整性:
- 实体完整性:主属性不能取空值
- 参照完整性:外码在其原本的表中应该有所对应
- 用户定义的完整性:属性要满足语义要求,例如性别只能是’男’或’女’
数据库的并发控制:
丢失更新(并发时一方的更新被覆盖了,像丢失了一样)

读脏(撤销更改)


不可重复读(两次读操作结果不一样)


两种锁(share和exclusive)

操作系统
操作系统的特点:
并发:指两个或多个事件在同一时间间隔内发生,微观上还是程序在分时地交替执行
区分并发和并行:

共享:指系统中的资源可供内存中多个并发执行的进程共同使用,主要包括两个方式,一种为互斥共享方式,例如如打印机,在一段时间内只允许一个进程访问该资源;另一种为同时访问方式,例如磁盘设备
虚拟: (没有并发性就谈不上虚拟性)是指一个物理上的实体变为若干个逻辑上的对应物,物理实体(前者)是实际存在的,而逻辑上对应物(后者)是用户感受到的
异步:在多道程序环境下,允许多个程序并发的执行,但由于资源有限,进程的执行不是一管到底的,而是走走停停已不可预知的速度向前推进
- 区分同步与异步:

- 区分同步与异步:
操作系统的作用:
操作系统作为用户与硬件系统之间的接口。
操作系统作为资源的管理者。

操作系统实现了对资源的抽象。
进程与线程:
进程:
进程是指一个具有独立功能的程序对某个数据集在处理机上的执行过程和分配资源的基本单位。每个进程包含独立的地址空间,进程各自的地址空间是私有的,只有执行自己地址空间中的程序,且只能访问自己地址空间中的数据,相互访问会导致指针的越界错误。
进程是操作系统进行资源分配的基本单位。
线程:
线程是独立调度的基本单位,一个进程中可以有多个线程。
线程是一个“轻量级进程”,是一个基本的 CPU 执行单元,也是程序执行流的最小单元。它可以减小程序在并发执行时所付出的时空开销,提高操作系统的并发性能。
线程共享进程拥有的全部资源,它不拥有系统资源,但是它可以访问进程所拥有的系统资源。线程没有自己独立的地址空间,它共享它所属的进程的空间。
进程与线程的区别

引入线程的目的是为了提高系统的并发性,这是因为,同一进程内的不同线程切换不会引起进程切换,从而避免系统调用,减少了系统开销。
进程间的通信方式(InterProcess Communication):
记下面的5种(下面的管道是匿名管道,FIFO是实名管道)
1.管道:速度慢,容量有限,只有父子进程能通讯
2.FIFO:任何进程间都能通讯,但速度慢
3.消息队列:容量受到系统限制,且要注意第一次读的时候,要考虑上一次没有读完数据的问题
4.信号量:不能传递复杂消息,只能用来同步
5.共享内存区:能够很容易控制容量,速度快,但要保持同步,比如一个进程在写的时候,另一个进程要注意读写的问题,相当于线程中的线程安全,当然,共享内存区同样可以用作线程间通讯,不过没这个必要,线程间本来就已经共享了同一进程内的一块内存

进程的状态:阻塞→就绪→运行

操作系统进程调度策略:
FCFS(先来先服务),优先级,时间片轮转,多级反馈

线程同步的方式:互斥量-信号量-事件信号

临界资源与临界区
临界资源即一次仅允许一个进程使用的资源,临界区即对临界资源进行访问的代码。为了互斥访问临界资源,每个进程在进入临界区之前,需要先进行检查。
管程
管程在功能上和信号量及PV操作类似,属于一种进程同步互斥工具,但是具有与信号量及PV操作不同的属性。
管程是由局部于自己的若干公共变量及其说明和所有访问这些公共变量的过程所组成的软件模块。
组成部分
1)局部于管程的共享变量;
2)对数据结构进行操作的一组过程;
3)对局部于管程的数据进行初始化的语句。死锁:
什么是死锁:
死锁是指多个进程运行过程中,因为争夺资源而造成的一种僵局,如果没有外力推进,那么处于僵局中的进程就无法继续执行。
死锁产生的四个必要条件:

预防/避免死锁:
【避免死锁】在资源的动态分配中,防止系统进入不安全的状态,例如银行家算法。
**银行家算法**:

一个例子:左图是初始条件,右图是解法,Work表示当前剩余资源数量,Allocation表示已经分配的资源数量,Need表示还需要的资源数量
【解除死锁】将系统从死锁中解脱出来,一般是撤销进程或剥夺资源。
【预防死锁】破坏产生死锁的四个必要条件:互斥、不可剥夺、请求与保持、循环等待

(破坏循环等待是给资源编号,所有进程都只能按顺序申请资源)
【检测死锁】
若每种资源只有一个,则资源分配图中出现环路是死锁的充分必要条件
若每种资源有多个,那么此状态的进程-资源分配图是不可完全简化的是死锁的充分必要条件
快表:
分页系统中内存数据需要两次的内存访问(一次是从内存中访问页表,找到物理块号,另一次是根据第一次得到的物理地址访问内存取出数据),引入快表机制,当需要访问内存数据,首先将页号在快表中查询,若找到则读取,找不到访问页表,再写入快表。当页表过多,需要较大的连续内存空间,这时采用多级页表。
虚拟内存:允许将一个作业分多次调入内存。可以用分页式、分段式、段页式存储管理来实现。
从逻辑上扩充内存容量。基于局部性原理,在程序装入时,可以将程序的一部分装入内存,而将其余部分留在外存,就可以启动程序执行。在程序执行过程中,当要访问的信息不在内存中,由操作系统将所需要的部分调入内存,然后继续执行。操作系统将暂时不用的内容换出到外存上,从而腾出空间来放调入内存的信息。系统好像为用户提供一个比实际内存大得多的存储器,称为虚拟存储器。
-

段提供二维地址空间,因为分段每段长度不同,需要段码+段内地址来确定具体位置,而分页存储由于页面大小固定,所以只需要一个物理地址即可计算出页码+页内地址
各自的好处:页是信息的物理单位,分页是为实现离散分配方式,以消减内存的外零头,提高内存的利用率。段则是信息的逻辑单位,它含有一组其意义相对完整的信息。分段的目的是为了能更好地满足用户的需要
页面置换算法:

哲学家进餐问题(利用信号量控制最多4个哲学家进程并发执行)
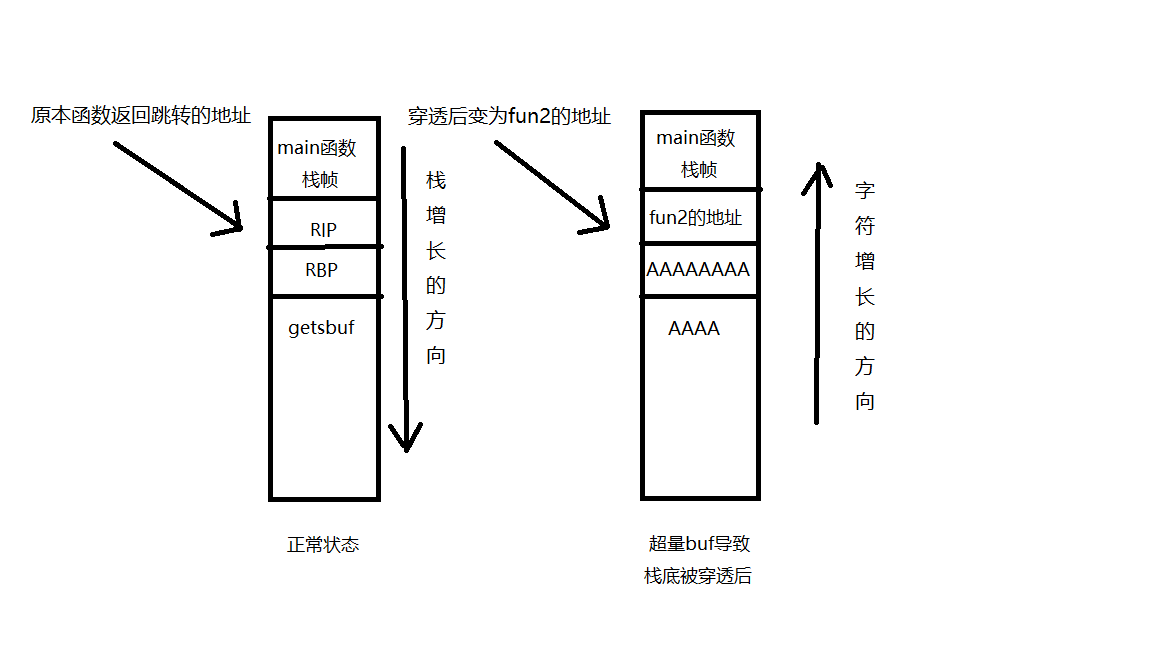
缓冲区溢出:
缓冲区溢出是指当 计算机 向缓冲区内填充数据位数时超过了缓冲区本身的容量,溢出的数据覆盖在合法数据上。
如何避免缓冲区溢出(第三条可以由操作系统执行)

5、使堆栈向高地址方向增长:栈是从高址向低址增长的,而缓冲区是从低址向高址填充的,所以缓冲区可能会覆盖掉栈中的内容
使用的机器堆栈压入数据时向高地址方向前进,那么无论缓冲区如何溢出,都不可能覆盖低地址处的函数返回地址指针,也就避免了缓冲区溢出攻击。但是这种方法仍然无法防范利用堆和静态数据段的缓冲区进行溢出的攻击。
中断、系统调用、库函数
【中断和系统调用的关系在于】当进程发出系统调用申请的时候,会产生一个软中断

-
先来先服务算法(FCFS)
最短寻找时间优先(SSTF)
扫描算法(SCAN)
循环扫描算法(C-SCAN)

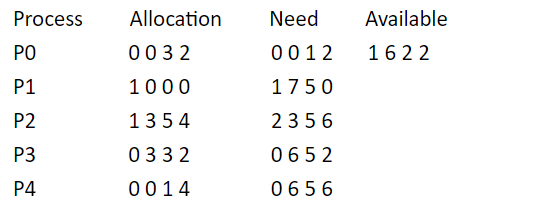
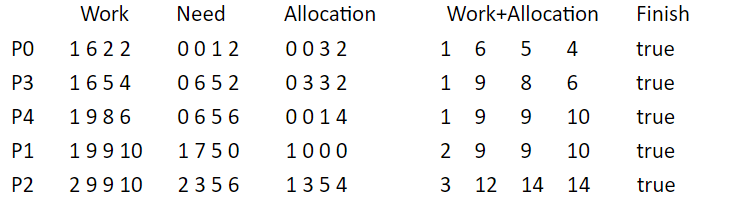
材料
附录
英语常见问答

- 本文链接:https://wan-nan.github.io/2022/07/15/%E5%86%B2%EF%BC%81/
- 版权声明:本博客所有文章除特别声明外,均默认采用 许可协议。