继之前的二叉树总结之后,由于图也是数据结构中一个重要的部分,还涉及一些离散的知识,所以也单独成文进行总结。
【参考】
C++中的构造函数
1 | struct node{ |
图的一些概念
无向图:顶点间的边为无序对
有向图:顶点间的边为有序对
简单图:不存在重复边和自环的图
多重图:与简单图相对
完全图:具有
n个顶点和n(n-1)/2条边的无向图有向完全图:具有
n个顶点和n(n-1)条边的有向图,每两个顶点之间都有两条方向相反的边连接的图。连通:在无向图中,若从顶点v到顶点w有路径存在,则称v和w是连通的。
连通图:图中任意两个顶点都是连通的
连通分量:无向图的极大连通子图称为连通分量
强连通图:有向图中,任意两个顶点之间都有双向路径
强连通分量:有向图中的极大强连通子图
一般对于有向图讨论的是其强连通性
而无向图只讨论其连通性
生成树:连通图的生成树是包含图中全部顶点的一个极小连通子图。若图中顶点数为n, 则它的生成树含有n − 1条边。
注意:包含无向图中全部顶点的极小连通子图,只有生成树满足条件,因为砍去生成树的任一条边,图将不再连通。
顶点的度、入度和出度
网:图中的边可以带权,带权图称为网
若一个图有n个顶点,并且有大于n − 1条边,则此图一定有环
图的存储结构
邻接矩阵
提前开好$n\times n$的二维数组(形似矩阵)
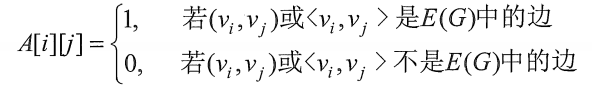
无向图的邻接矩阵一定是对称矩阵
邻接表
对于稀疏图,边数较少,邻接矩阵会耗费大量的空间,此时使用邻接表
也有逆邻接表来方便入度的计算
十字链表:
十字链表是有向图的一种链式存储结构。
十字链表的好处就是因为把邻接表和逆邻接表整合在了一起, 这样既容易找到以V为尾的弧,也容易找到以V为头的弧,因而容易求得顶点的出度和入度。
而且它除了结构复杂一点外,其实创建图算法的时间复杂度是和邻接表相同的,因此,在有向图的应用中,十字链表是非常好的数据结构模型。
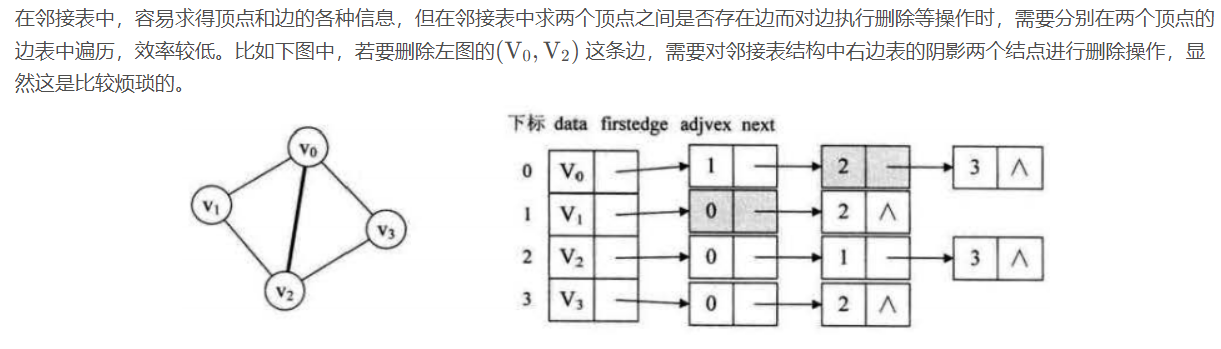
邻接多重表:
邻接多重表是无向图的另一种链式存储结构。

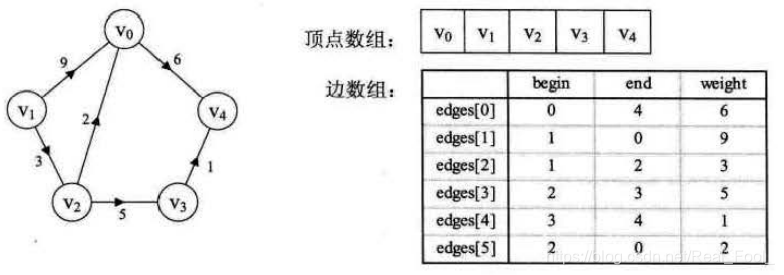
边集数组
更适合对边依次进行处理的操作,而不适合对顶点相关的操作。
图的重要算法
最小生成树(Prim&Kruskal)
最小生成树(Minimum Spanning Tree):图的所有生成树中具有边上的权值之和最小的树。
基于带权图得到最小生成树的方法:
普里姆(Prim)算法:从任意一个结点出发进行繁衍
时间复杂度$O(n^2)$,适合稠密图


1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36unordered_set<Edge, EdgeHash, EdgeEqual> primMST(Graph graph){
// 装边的最小堆
auto cmp = [](const Edge& e1, const Edge& e2){
return e1.weight > e2.weight;
};
priority_queue<Edge, vector<Edge>, decltype(cmp)> smallQueue(cmp);
// 判断节点是否访问过
unordered_set<Node, NodeHash, NodeEqual> node_set;
unordered_set<Edge, EdgeHash, EdgeEqual> result;
for(auto ite: graph.nodes){
if(node_set.find(*ite.second) == node_set.end()){
// 如果没有访问,将其标记为访问过,并把它对应的边放入最小堆
node_set.insert(*ite.second);
for(Edge* edge: ite.second->edges){
smallQueue.push(*edge);
}
// 在当前这个图中寻找最小生成树
while(!smallQueue.empty()){
// 从堆中取出一个最小权重边,并取出对应节点
Edge help_edge = smallQueue.top();
smallQueue.pop();
Node edge_to = *(help_edge.to);
// 然后判断这个节点是否被访问过,如果没有则将这个边加入边集
if(node_set.find(edge_to) == node_set.end()){
result.insert(help_edge);
node_set.insert(edge_to); // 标记edge_to也已经访问过了
for(Edge *newEdge: edge_to.edges){
smallQueue.push(*newEdge);
}
}
}
}
}
return result;
}克鲁斯卡尔(Kruskal)算法【贪心】:按照权值从小到大的顺序依次选取图中的边,同时确保不会成环(并查集)
时间复杂度$O(eloge)$,适合稀疏图

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27unordered_set<Edge, EdgeHash, EdgeEqual> kruskalMST(Graph graph){
auto cmp = [](const Edge& a, const Edge& b){
return a.weight > b.weight; // 最小堆
};
vector<Node*> list;
for(auto ite: graph.nodes){
list.push_back(ite.second);
}
UnionFindSet unionFind(list); // 建立并查集
priority_queue<Edge, vector<Edge>, decltype(cmp)> smallQueue(cmp);
for(auto edge: graph.edges){
smallQueue.push(*edge);
}
// 构造选中的输出边集
unordered_set<Edge, EdgeHash, EdgeEqual> result;
while(!smallQueue.empty()){
Edge edge = smallQueue.top();
smallQueue.pop();
if(!unionFind.isSameSet(edge.from, edge.to)){
// 判断是否为一个环,如果一个边的两端节点为一个集合,那么必为一个闭合环
result.insert(edge);
unionFind.Union(edge.from, edge.to);
}
}
return result;
}稠密图是边的数量较多。稠密和稀疏是对于边的数量来说的
Kruskal算法时间复杂度和边数e相关,所以适合稀疏图,使用邻接表存储
Prim算法时间复杂度只和结点数n相关,所以适合稠密图,使用邻接矩阵存储
最短路径
无权图:单源最短路径问题使用BFS解决【同时要求边没有权重】
对于带权图
单源最短路径用迪杰斯特拉
本质是动态规划,时间复杂度$O(V^2)$
画一个表辅助解题
多源最短路径用弗洛伊德
本质是动态规划,时间复杂度$O(V^3)$(因为把任意两个点之间的最短距离都算出来了)
画多个表辅助解题
拓扑排序
参考之前的文章
关键路径
从源点到汇点具有最大长度的路径叫关键路径,在关键路径上的活动叫关键活动。

用Dijkstra算法也可以求最长路径【不能!!!】可以用一次拓扑排序+dp求最长路径

Dijkstra 不优化:V^2
优先队列优化:(E+V)logV
Bellman Ford不优化:O(VE)
队列优化后:O(VE)
优先队列优化了选择最近结点的过程,优先队列存的是当前能从源点到达的结点。
基于Bellman-Ford,再可以确定,松弛操作必定只会发生在最短路径前导节点松弛成功过的节点上,用一个队列记录松弛过的节点,可以避免冗余计算。

“Bellman-Ford算法不是选取最小的边进行选择,而是根据每一条边,依次对距离数组进行更新(所以不优化是VE),所以一个点可能会被访问多次”
找最长路径时,拓扑与Dijkstra的区别:

Dijkstra结合优先队列优化后的步骤:

- 本文链接:https://wan-nan.github.io/2022/08/31/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84-%E5%9B%BE-%E6%80%BB%E7%BB%93/
- 版权声明:本博客所有文章除特别声明外,均默认采用 许可协议。