消息队列的作用:
- 解耦
- 削峰
- 异步
- 日志处理
什么是消息队列?
消息队列(MQ)指保存消息的一个容器,本质是个队列。
但这个队列,需要支持高吞吐,高并发,并且高可用。
业界常见的消息队列:
Kafka:分布式的、分区的、多副本的日志提交服务,在高吞吐场景下发挥较为出色
RocketMQ:低延迟、强一致、高性能、高可靠、万亿级容量和灵活的可扩展性,在一些实时场景中运用较广
Pulsar:是下一代云原生分布式消息流平台,集消息、存储、轻量化函数式计算为一体,采用存算分离的架构设计
BMQ:和Pulsar架构类似,存算分离,初期定位是承接高吞吐的离线业务场景,逐步替换掉对应的Kafka集群
Kafka
如何使用Kafka
创建集群→新增Topic→编写生产者逻辑→编写消费者逻辑
基本架构
基本概念:
Topic:逻辑队列,不同Topic可以建立不同的Topic
Cluster:物理集群,每个集群中可以建立多个不同的Topic
Producer:生产者,负责将业务消总发送到Topic中
Consumer:消费者,负责消费Topic中的消息
ConsumerGroup:消费者组,不同组Consumer消费进度互不干涉
Partition【分片】:通常topic会有多个分片,不同分片之间消息是可以并发来处理的,这样提高单个Topic的吞吐

Offset:消息在partition内的相对位置信息,可以理解为唯一ID,在partition内部严格递增。

Replica:分片的副本,分布在不同的机器上,可用来容灾,Leader对外服务 ,Follower异步去拉取leader的数据进行一个同步,如果Leader挂掉了,可以将Follower提升成Leader再对外进行服务;每个分片有多个Replica,Leader Replica将会从ISR(In-Sync Replicas)中选出
ISR:意思是同步中的副本,对于Follower来说, 始终和leader是有一定差距的,但只有当这个差距比较小的时候,我们才可以将这个follower副本加入到ISR中,不在ISR中的副本是不允许提升成Leader的(下图中的Replica3与Leader差距过大,不允许加入ISR)

Kafka中副本分布图示例:

上面这幅图代表着Kafka中副本的分布图。图中一个Broker代表一个Kafka的节点, 所有的Broker节点最终组成了一个集群。
图中整个集群,包含了4个Broker机器节点,集群有两个Topic,分别是Topic1和Topic2, Topic1有两个分片, Topic2有1个分片,每个分片都是三副本的状态。
这里中间有一个Broker同时也扮演 了Controller的角色,Controller是整个集群的大脑,负责对副本和Broker进行分配。
Kafka整体架构:

在集群的基础上,还有一个模块是ZooKeeper, 这个模块存储了集群的元数据信息,比如副本的分配信息等等,Controller计算好的方案都会放到这个地方
生产消费流程(好的特性)
一条消息的“自述”:
Producer→Broker→Consumer
Producer批量发送消息(Batch)
批量发送可以减少IO次数,从而加强发送能力
增大吞吐
Producer数据压缩
通过压缩,减少消息大小,降低带宽流量,以应对可能出现的网络带宽不足的问题。目前支持Snappy、 Gzip、LZ4、ZSTD压缩算法
Broker采用顺序写(末尾追加)的方式进行写入,以提高写入效率
Broker消息索引(稀疏索引)
寻找消息的机制
Broker零拷贝:
减少拷贝次数,加快消息数据传输速度

Consumer从Broker中读取数据,通过sendfile的方式, 将磁盘读到os内核缓冲区后,直接转到NIC buffer进行网络发送
Producer生产的数据持久化到broker,采用mmap文件映射,实现顺序的快速写入(从用户态直接写入磁盘,不用再写内核态,减少内存拷贝次数)Consumer的rebalance(关于Consumer如何分配Partition)
背景是Consumer可以并发消费Partition,那么一个Consumer要如何确定自己该消费哪个Partition呢?(Low Level)手动分配:在启动consumer的时候预先设定好该consumer会消费的partition;优点是快,但是这样有许多弊端,不能容灾,且不够灵活
(High Level)自动分配:对于不同的Consumer Group来讲,都会在Broker集群中选取一台Broker当做Coordinator,而Coordinator的作用就是帮助Consumer Group进行分片的分配,也叫做分片的rebalance,使用这种方式,如果ConsumerGroup中有发生宕机,或者有新的Consumer加入,整个partition和Consumer都会重新进行分配来达到一个稳定的消费状态
Consumer Rebalance过程示意图

总结:可以帮助Kafka提高吞吐或者稳定性的功能?
Producer:批量发送、数据压缩
Broker:顺序写,消息索引,零拷贝
Consumer:Rebalance
存在的问题
Kafka数据复制问题:
由一些特殊场景下的节点大量【重启/替换/扩容/缩容】(Kafka集群的这类运维操作都会导致节点的变动,都会有数据复制带来的时间成本问题)引发的,会使某个Broker承载大量帮其他节点进行数据同步的时间开销

Kafka负载不均衡:
场景:

这个场景当中,同一个Topic有4个分片,两副本(因为Partition分布在两个Broker上,即两个机器上),可以看到,对于分片1来说,数据量是明显比其他分片要大的,当我们机器IO达到瓶颈的时候,可能就需要把第一台Broker上面的Partition3迁移到其他负载小的Broker上面,但这个为了降低Broker1的IO,平衡副本之间负载的迁徙操作同样是数据复制操作,同样会引起Broker1的IO升高。所以就需要权衡IO设计出一个极其复杂的负载均衡策略。
Kafka问题总结:
运维成本高
对于负载不均衡的场景,解决方案复杂
没有自己的缓存,完全依赖Page Cache
Controller和Coordinator和Broker在同一进程中,大量IO会造成其性能下降
【Controller是整个集群的大脑,负责对副本和Broker进行分配】
【Coordinator的作用就是帮助Consumer Group进行分片的分配,也叫做分片的rebalance】
BMQ
兼容Kafka协议,存算分离,云原生消息队列
架构模型
BMQ架构图

特点:
兼容Kafka,所以Producer和Consumer都兼容
加入Proxy Cluster和Broker Cluster,且Controller和Coordinator被独立出来进行部署
存算分离,可以在底层用另外的分布式存储系统Distributed Storage System进行
Meta Storage System类似Kafka中的Zoo Keeper,用于存储集群的元数据信息,比如副本的分配信息等等,Controller计算好的方案都会放到这个地方
读写分离(类似数据库):Proxy Cluster处理读请求,Broker Cluster处理写请求
得益于存算分离+读写分离,Proxy和Broker都是无状态的,不会存数据,没有数据复制,降低了运维成本:

BMQ不会出现Kafka中的负载不均问题
BMQ底层是借助HDFS进行存储的,HDFS写文件流程:

通过前面的介绍,我们知道了,同一个副本是由多个segment组成,我们来看看BMQ对于单个文件写入的机制是怎么样的,首先客户端写入前会选择一定数量的DataNode,这个数量是副本数,然后将一个文件写入到这三个节点上, 切换到下一个segment之后,又会重新选择三个节点进行写入。这样一来,对于单个副本的所有segment来讲,会随机的分配到分布式文件系统的整个集群中
和Kafka比较:

对于Kafka分片数据的写入,是通过先在Leader上面写好文件,然后同步到Follower上,所以对于同一个副本的所有Segment都在同一台机器上面。这样就会存在之前我们所说到的单分片过大导致负载不均衡的问题。
但在BMQ集群中,因为对于单个副本来讲,segment是随机分配到不同的节点上面的,因此BMQ不会存在Kafka的负载不均问题。
读写流程
Broker-Partition状态机【写入过程】
保证任意分片在同一时刻只能在一个Broker上存活

对于写入的逻辑来说,我们还有一个状态机的机制,用来保证不会出现同一个分片在两个Broker上同时启动的情况,另外也能够保证一个分片的正常运行。
首先,Controller做好分片的分配之后,如果当前分片分到了某个Broker,首先会start这个分片,然后进入Recover状态,这个状态主要有两个目的:
- 获取分片写入权利:也就是说,对于hdfs来讲,只会允许我一个分片进行写入,只有拿到这个权利的分片才能写入
- 应对异常情况下的恢复:第二个目的是如果上次分片是异常中断的,没有进行save checkpoint,这里会重新进行一次save checkpoint,然后就进入了正常的写流程状态,创建文件,写入数据,到一定大小之后又开始建立新的文件进行写入。
状态机图中的Recover状态详解:
Writer Thread下面的流程对应上一张图白框里的流程

数据校验: CRC, 验证参数是否合法
校验完成后,会把数据放入Buffer中,通过一个异步的Write Thread线程将数据最终写入到底层的存储系统当中
这里有一个地方需要注意一下, 就是对于业务的写入来说,可以配置返回方式,可以在写完缓存之后直接返回,另外也可以等数据真正写入存储系统后再返回,对于这两个来说前者损失了数据的可靠性,带来了吞吐性能的优势,因为只写入内存是比较快的,但如果在下一次flush前发生宕机了, 这个时候数据就有可能丢失了,后者的话,因为数据已经写入了存储系统,这个时候也不需要担心数据丢失,相应的来说吞吐就会小一些。
我们再来看看Thread的具体逻辑,(Write Data)首先会将Buffer中的数据取出来, 调用底层写入逻辑,(flush)在一定的时间周期上去flush, (Build Index)flush完成后开始建立Index,也就是offset和timestamp对于消息具体位置的映射关系;Index建立好以后,会save一次checkpoint, 也就表示,checkpoint后的数据是可以被消费的,我们想一下, 如果没有checkpoint的情况下会发生什么问题,如果flush完成之后宕机,index还没有建立,这个数据是不应该被消费的,可能会导致数据和index不对应。有了checkpoint就可以保证宕机发生后,也会先Build Index,再进行数据的写入。最后当文件到达一定大小之后,需要建立一个新的segment文件来写入。
状态机图中的Failover状态详解:
如果在向HDFS中写入segment时出现某个DataNode不能写入,这个时候不会等待这个DataNode恢复,为了保证高可用性,会重新寻找可以写入的DataNode进行写入
Proxy【读取流程】

Wait阶段详解:
consumer发送的Fetch Request如果没有fetch到指定大小的数据,proxy会先等待一段时间,再返回用户侧,这样就可以降低fetch请求的IO次数。
经过Wait流程后,Proxy会先到Cache中查找数据,找到直接返回,未找到再去存储系统中查找,首先open file,再通过Index找到数据的位置,再读取数据并返回。
BMQ多机房部署:
线上高可用服务除了防止单机故障的意外影响,也要防止机房级别故障带来的影响。
Proxy对Broker是一对多跨机房访问的

高级特性
泳道→Databus→Mirror→Index→Parquet

泳道:
解决主干泳道流量隔离问题以及泳道资源重复创建问题
为了测试环境重新建立一个Topic

DataBus
Kafka生产者代码:

直接使用原生SDK会有什么问题?
1.客户端配置较为复杂
2.不支持动态配置,更改配置需要停掉服务
3.对于latency不是很敏感的业务,batch 效果不佳
Databus的架构:

对应上面原生SDK的缺陷,Databus的优势:
1.简化消息队列客户端复杂度
2.解耦业务与Topic
3.缓解集群压力,提高吞吐(对于高吞吐的业务比较友好,但是对于latency要求高的业务不太友好)
Mirror
解决跨Region的问题(Region是较大的地区概念,比如不同国家)
不能采取之前多机房部署的方式,那样写数据的延迟会非常高。
可以在不同Region之间部署Mirror,进行Region之间的异步同步,如下图所示:

使用Mirror通过最终一致的方式,解决跨Region读写问题
Index
如果希望通过写入的LogID、UserID或者其他业务字段进行消息的查询,应该怎么做?

直接在BMQ中将数据结构化,配置索引DDL,异步构建索引后,通过Index Query服务读出数据。
Parquet
Apache Parquet是Hadoop生态圈中一种新型列式存储格式,它可以兼容Hadoop生态圈中大多数计算框架(Hadoop、Spark等), 被多种查询引擎支持(Hive、Impala、 Dill等)。
行式存储和列式存储:

- 行式存储在查询某个表中所有的列数据时更快,如
select * from table where id = 1 - 列式存储在查询某个特定的列时更快
显然目前列式存储相应的查询方式更为多见
- 行式存储在查询某个表中所有的列数据时更快,如
对于Producer生产的消息,原本的存储方式更像是列存储,可以通过存入Parquet Engine,将数据结构化,使用不同的方式构建Parquet格式文件,方便后续的数据分析

总结:
- BMQ的架构模型(解决Kafka存在的问题)
- BMQ读写流程(Failover 机制,写入状态机)
- BMQ高级特性(泳道、Databus、Mirror、Index、 Parquet)
RocketMQ
RocketMQ基本概念

RocketMQ架构


数据流也是通过Producer发送给Broker集群,再由Consumer进行消费
Broker节点有Master和Slave的概念
NameServer为集群提供轻量级服务发现和路由
RocketMQ存储模型:

接下来我们来看看RocketMQ消息的存储模型,对于一个Broker来说所有的消息的会append到一个CommitLog 上面,然后按照不同的Queue,重新
Dispatch到不同的Consumer中,这样Consumer就可以按照Queue进行拉取消费 ,但需要注意的是,这里的ConsumerQueue所存储的并不是真实的数据,真实的数据其实只存在CommitLog中,这里存的仅仅是这个Queue所有消息在CommitLog上面的位置,相当于是这个Queue的一个密集索引RocketMQ高级特性
事务场景:
在下面的场景中,【库存记录-1】和【消息队列】两步需要保证在同一个事务内
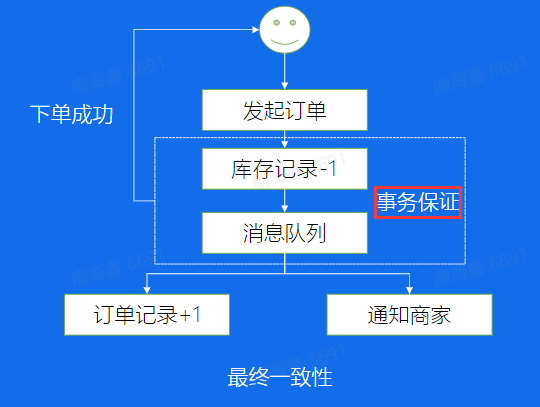

即在Producer添加了一个两阶段提交
延迟发送:

可以延迟发送消息队列中的消息
原理是添加了ScheduleTopic来单独处理需要延迟发送的消息,在到了延迟的时间后再回写进CommitLog

处理失败:
消费消息失败之后会进行重试,超过一定的重试次数会送入Dead Letter死信队列,不会再重试尝试发送

RocketMQ小结:
- RocketMQ的基本概念(Queue, Tag)
- RocketMQ的底层原理(架构模型、存储模型)
- RocketMQ的高级特性(事务消息、重试和死信队列,延迟队列)
总结
- 前世今生:消息队列发展历程
- Kafka:基本概念、架构设计、底层原理、架构缺点
- BMQ:架构设计、底层原理、Kafka 比较、高级特性
- RocketMQ:架构设计、底层原理、高级特性
- 本文链接:https://wan-nan.github.io/2023/02/08/%E6%B6%88%E6%81%AF%E9%98%9F%E5%88%97%E7%AC%94%E8%AE%B0/
- 版权声明:本博客所有文章除特别声明外,均默认采用 许可协议。