基本概念
本地函数调用
下图是一个本地函数调用的举例,需要函数指针、参数压栈等操作

远程函数调用(RPC - Remote Procedure Calls)
RPC需要解决问题:
函数映射(从函数名到函数的地址的映射)
在本地函数调用中通过函数指针进行,在远程函数调用中caller和callee完全不在同一个地址空间中,无法使用函数指针,此时每个函数需要有一个自己的ID,RPC时需要附上这个ID
数据转换成字节流(参数等数据的传输方式)
本地函数调用中只需要压栈即可传参,即将参数保存进内存即可;RPC中需要客户端先将参数数据转换成字节流,传给服务端后,服务端再转成自己可以读取的数据
网络传输
数据传输需要经过网络,需要确保网络传输数据时的高效稳定
RPC概念模型:
下图是实际情况下一次RPC调用的完整过程:

RPC过程的5个模型组成:
User、User-Stub、RPC-Runtime、Server-Stub、Server
一次RPC的完整过程:

上图中的一些概念:
IDL (Interface description language)文件
IDL通过一种中立的方式来描述接口,使得在不同平台上运行的对象和用不同语言编写的程序可以相互通信生成代码GenCode
通过编译器工具把IDL文件转换成语言对应的静态库
编解码Encoder/Decoder
从内存中表示到字节序列的转换称为编码,反之为解码,也常叫做序列化和反序列化
通信协议Protocol
规范了数据在网络中的传输内容和格式。除必须的请求/响应数据外,通常还会包含额外的元数据
网络传输Transfer
通常基于成熟的网络库走TCP/UDP传输
RPC的好处:
- 单一职责,有利于分工协作和运维开发
- 可扩展性强,资源使用率更优
- 故障隔离,服务的整体可靠性更高
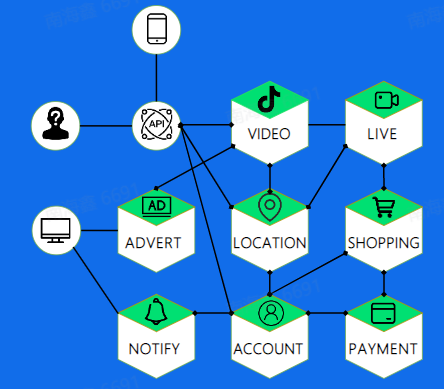
RPC的问题:
服务宕机,对方应该如何处理?
在调用过程中发生网络异常,如何保证消息的可达性?
请求量突增导致服务无法及时处理,有哪些应对措施?
这些问题将由RPC框架解决
分层设计
主要分三层:编解码层、协议设计层、网络通信层
分层设计:(以Apache Thrift为例)

解编码层
编解码层:数据格式
编解码的数据格式有以下三种
语言特定的格式
许多编程语言都内建了将内存对象编码为字节序列的支持,例如Java有
java.io.Serializable(和某种语言绑定,缺乏兼容性)文本格式
JSON、XML、CSV 等文本格式,具有人类可读性(性能较差且不易用)
二进制编码
具备跨语言和高性能等优点,常见有Thrift的BinaryProtocol,Google的Protobuf 等
二进制编码举例:TLV编码

解编码层:选型
选择编码数据格式的时候要考虑三个方面:
兼容性:支持自动增加新的字段,而不影响老的服务,这将提高系统的灵活度
通用性:支持跨平台、跨语言
性能:从空间和时间两个维度来考虑,也就是编码后数据大小和编码耗费时长
协议设计层
编解码是数据如何转化成字节流
协议层是设计数据的形式是怎样的
协议是双方确定的交流语义,比如:我们设计一个字符串传输的协议,它允许客户端发送一个字符串, 服务端接收到对应的字符串。这个协议很简单,首先发送一个4字节的消息总长度, 然后再发送1字节的字符集charset长度,接下来就是消息的payload,字符集名称和字符串正文。
有两种协议:
- 特殊结束符:过于简单,对于一个协议单元必须要全部读入才能够进行处理,除此之外必须要防止用户传输的数据不能同结束符相同,否则就会出现紊乱
HTTP协议头就是以回车(CR)加换行(LF)符号序列结尾。 - 变长协议:一般都是自定义协议,有header和payload组成,会以定长加不定长的部分组成,其中定长的部分需要描述不定长的内容长度,使用比较广泛

- 特殊结束符:过于简单,对于一个协议单元必须要全部读入才能够进行处理,除此之外必须要防止用户传输的数据不能同结束符相同,否则就会出现紊乱
一个协议的举例:

协议解析
先寻找MagicNumber,即上图中的HEADER MAGIC
再寻找PayloadCodec,即上图中的PROTOCOL ID和TRANSFORM ID
然后就可以对payload进行解码了
网络通信层
Sockets API
即计网建立TCP连接用到的那个Sockets

网络库
工程实践中会使用封装好的网络库

关键指标
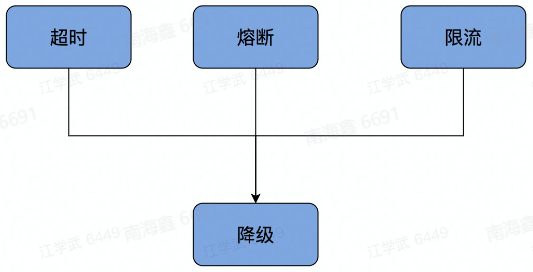
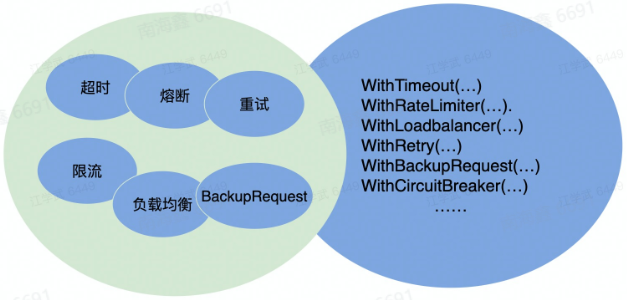
稳定性 - 保障策略
- 熔断:保护调用方,防止被调用的服务出现问题而影响到整个链路
- 限流:保护被调用方,防止大流量把服务压垮
- 超时控制:避免浪费资源在不可用节点上
稳定性 - 请求成功率
- 负载均衡
- 重试
稳定性 - 长尾请求
P99后面的请求视为长尾请求
解决:
- Backup Request备份请求
稳定性 - 注册中间件
MiddleWare即为中间件
Kitex Client和Server的创建接口均采用Option模式,提供了极大的灵活性,很方便就能注入这些稳定性策略
易用性:
Kitex使用Suite来打包自定义的功能,提供「一键配置基础依赖」的体验
开箱即用
合理的默认参数选项、丰富的文档
周边工具
生成代码工具、脚手架工具
扩展性
扩展点较多,如MiddleWare等等
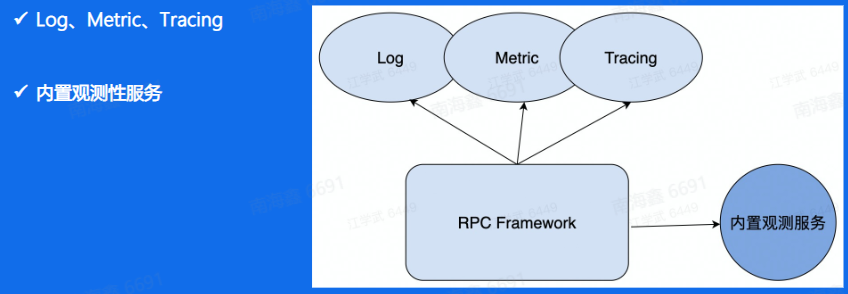
观测性:
高性能:
高性能体现在:高吞吐+低延迟
总结:
- 框架通过中间件来注入各种服务治理策略,保障服务的稳定性
- 通过提供合理的默认配置和方便的命令行工具可以提升框架的易用性
- 框架应当提供丰富的扩展点,例如核心的传输层和协议层
- 观测性除了传统的Log、Metric 和Tracing之外,内置状态暴露服务也很有必要
- 性能可以从多个层面去优化,例如选择高性能的编解码协议和网络库
企业实践
整体架构 - Kitex
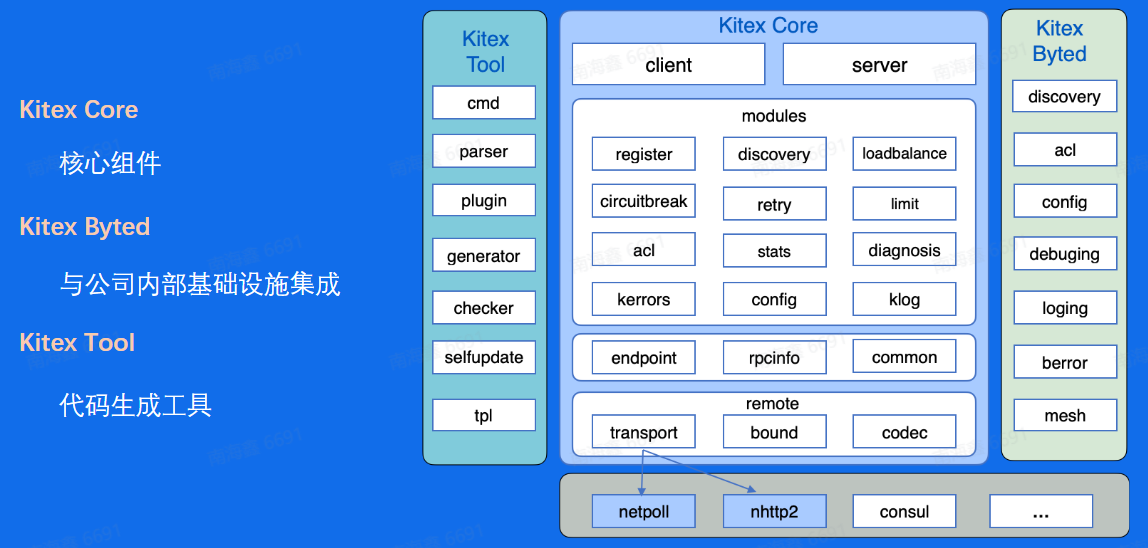
core是它的的主干逻辑,定义了框架的层次结构、接口,还有接口的默认实现,如中间蓝色部分所示,最上面client和server是对用户暴露的,client/server option的配置都是在这两个package中提供的,还有client/server的初始化, 在第二节介绍kitex_gen生成代码时,大家应该注意到里面有client.go和sever.go,虽然我们在初始化client时调用的是kitex_gen中的方法,其实大家看kitex_gen下service package代码就知道,里面是对这里的client/server的封装。
client/server 下面的是框架治理层面的功能模块和交互元信息,remote是 与对端交互的模块,包括编解码和网络通信。
右边绿色的Byted是对字节内部的扩展,集成了内部的二方库还有与字节相关的非通用的实现,在第二节高级特性中关于如何扩展kitex里有介绍过,Byted部分是在生成代码中初始化client和server时通过suite集成进来的,这样实现的好处是与字节的内部特性解耦,方便后续开源拆分。
左边的tool则是与生成代码相关的实现,我们的生成代码工具就是编译这个包得到的,里面包括IDL解析、校验、代码生成、插件支持、自更新等, 未来生成代码逻辑还会做一些拆分,便于给用户提供更友好的扩展
自研网络库 - 背景
原生库无法感知连接状态
在使用连接池时,池中存在失效连接,影响连接池的复用。
原生库存在goroutine暴涨的风险
一个连接一 个goroutine的模式,由于连接利用率低下,存在大量goroutine 占用调度开销,影响性能。
自研网络库 - Netpoll
解决无法感知连接状态问题
引入epoll主动监听机制,感知连接状态
解决goroutine暴涨的风险
建立goroutine池,复用goroutine
提升性能
引入Nocopy Buffer,向上层提供NoCopy的调用接口,编解码层面零拷贝
扩展性设计

性能优化 - 网络库优化
调度优化
epoll wait在调度上的控制
gopool重用goroutine降低同时运行协程数
LinkBuffer
读写并行无锁,支持nocopy地流式读写
高效扩缩容
Nocopy Buffer池化,减少GC
Pool
引入内存池和对象池,减少GC开销
性能优化 - 编解码优化
Codegen
预计算并预分配内存,减少内存操作次数,包括内存分配和拷贝Inline减少函数调用次数和避免不必要的反射操作等
自研了Go语言实现的Thrift IDL解析和代码生成器,支持完善的Thrift IDL语法和语义检查,并支持了插件机制 - Thriftgo
JIT(Just In Time)
使用JIT编译技术改善用户体验的同时带来更强的编解码性能,减轻用户维护生成代码的负担
基于JIT编译技术的高性能动态Thrift 编解码器 - Frugal
合并部署
微服务过微,传输和序列化开销越来越大
将亲和性强的服务实例尽可能调度到同一个物理机,远程RPC调用优化为本地IPC调用

这样合并部署需要:
- 中心化的部署调度和流量控制
- 基于共享内存的通信协议
- 定制化的服务发现和连接池实现
- 定制化的服务启动和监听逻辑
小结:
介绍了Kitex的整体架构
介绍了自研网络库Netpoll 的背景和优势
从扩展性和性能优化两个方面分享了相关实践
介绍了内部正在尝试落地的新的微服务形态:合并部署
课程总结
从本地函数调用引出RPC的基本概念
重点讲解了RPC框架的核心的三层,编解码层、协议层和网络传输层
围绕RPC框架的核心指标,例如稳定性、可扩展性和高性能等,展开讲解相关的知识
分享了字节跳动高性能RPC框架Kitex的相关实践
- 本文链接:https://wan-nan.github.io/2023/02/10/RPC%E6%A1%86%E6%9E%B6%E7%AC%94%E8%AE%B0/
- 版权声明:本博客所有文章除特别声明外,均默认采用 许可协议。