Glossary
| abbr. | full name | note |
|---|---|---|
| RDMA | Remote Direct Memory Access | |
| RoCE | RDMA over Converged Ethernet | |
| PFC | Priority-based Flow Control | |
| HOL blocking | Head-of-Line blocking | 队头阻塞 |
| HPC | High Performance Computing | |
| ToR | Top of Rack | 架顶式(ToR)是一种常见的交换机到服务器连接架构 |
| NVM | Non-Volatile Memory | 非易失性存储 NVM和RDMA可以称得上加速数据中心应用的两架马车 分别从存储和网络方面满足高带宽、低延迟的需求 |
| ECMP | Equal-Cost Multi-Path routing | 等价多路径路由 数据中心内负载均衡-ECMP的使用分析 |
| FCoE | Fibre Channel over Ethernet | 存储网络 – 了解FCoE的八个技术细节 |
| RED | Random Early Detection | 旨在将队列的平均长度保持在较低的值,同时允许一定量的突发报文 |
| IOPS | Input/Output Per Second | 衡量存储介质性能的主要指标之一 IOPS是指每秒钟系统能处理的读写请求数量 |
| MMU | memory management unit | 交换机buffer |
| MTU | Maximum Transmission Unit | 什么是MTU(Maximum Transmission Unit)? |
| INT | in-network telemetry | HPCC用的 |
CC
DCTCP是window-based CC
DCQCN和TIMELY都是rate-based CC
(DCTCP)Data center tcp
该读$$\S3.4\ Guidelines\ for\ choosing\ parameters$$了,基本了解了数据中心的通信结构、负载组成、传统TCP在数据中心的不足及其成因;DCTCP算法流程、效果、数学推导。
后面基本是参数设置和实验环节
motivation
“(the soft real-time application) generate a diverse mix of short and long flows, and require three things from the data center network: slow latency for short flows, high burst tolerance, and high utilization for long flows.”
“to meet the requirements of such a diverse mix of short and long flows, switch buffer occupancies need to be persistently low, while maintaining high throughput for the long flows.”
“DCTCP is designed to do exactly this.”
Algorithm
算法分为三部分:
Simple Marking at the Switch:
交换机按照阈值k来标记数据包,交换机的队列长度大于k时,交换机会在数据包的在IP报头中打上CE(Congestion Experienced)标记
与RED算法不同的是,DCTCP的标记based on instantaneous, instead of average queue length.
ECN-Echo at the Receiver:
The only difference between a DCTCP receiver and a TCP receiver is
the way information in the CE codepoints is conveyed back to the sender.
接收端如何确定是否回复ECN-Echo(ECE)?考虑到Delayed ACKs,Receiver的行为遵循下面的FSM:
如果当前数据包中的CE标志与前一个不同,则接收方立即发送ACK。 当CE标志不变时,它会像正常的Delayed ACK一样。
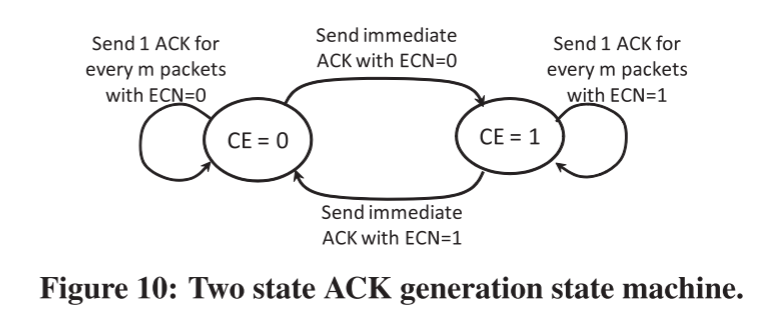
The states correspond to whether the last received packet was marked with the CE codepoint or not.
Controller at the Sender:
发送端如何对ECE做出反应?
发送端计算【收到的数据包中被标记ECE的比例】,称为α,对于每个数据窗口(大约一个RTT)更新一次,计算公式如下所示:
$$
\alpha ← (1 − g) \times \alpha + g \times F
$$
exponential moving average——移动指数平均值其中$$F$$是在最近的一个窗口中被标记ECE的包的比例,$$0<g<1$$是在$$\alpha$$的估计中给新样本与过去样本的权重。
α估计队列大小大于K的概率。本质上,α接近0表示低拥塞,α接近1表示高拥塞水平。
The only difference between a DCTCP sender and a TCP sender is
in how each reacts to receiving an ACK with the ECN-Echo flag set.
DCTCP保留了TCP中的慢启动、拥塞避免中的Additive increase、丢包后的Recovery,不同之处在于对ECE的反应:
$$
cwnd ← cwnd \times (1 − \alpha/2)
$$
Analysis
计算队列长度的式子:
$$
Q(t) = NW(t) −C \times RTT
$$We consider N infinitely long-lived flows with identical round-trip times RTT, sharing a single bottleneck link of capacity C.
We further assume that the N flows are synchronized; i.e., their “sawtooth” window dynamics are in-phase. Of course, this assumption is only realistic when N is small.
C应该就是BandWidth(?)C×RTT就是BDP
锯齿形波动的振幅:振幅越小,队列长度保持的越稳定,CC性能越好
The most important of these is the amplitude of oscillations, which quantifies how well DCTCP is able to maintain steady queues, due to its gentle proportionate reaction to congestion indications.
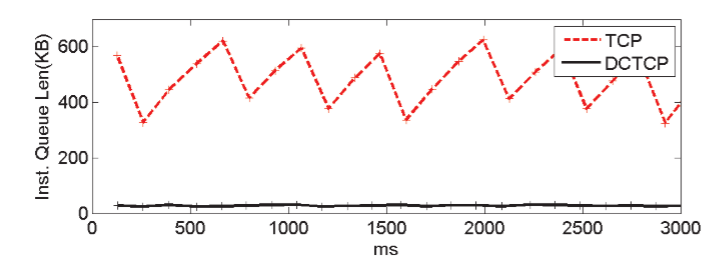
上图中TCP和DCTCP的差异在于下面的计算:

TCP的amplitude的数量级是$$O(C\times RTT)$$,而DCTCP的amplitude只有 $$O(\sqrt{C\times RTT})$$
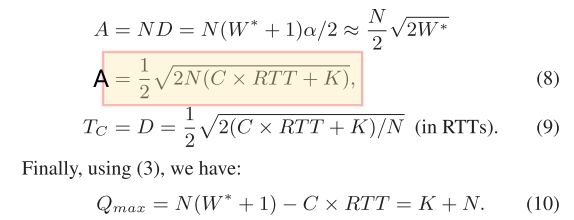
(DCQCN) Congestion Control for Large-Scale RDMA Deployments
该读$$\S5.\ ANALYSIS\ OF\ DCQCN$$了,基本了解了RDMA在网络领域的背景知识,以及DCQCN的算法设计
后面基本是流体模型、参数设置和实验环节
(本论文参考这个翻译读了不少)还不错的翻译:【SIGCOMM 2015】出道即是巅峰!DCQCN:数据中心大规模部署RDMA的拥塞控制方案
why RDMA need drop-free network?
【为什么RDMA需要无损网络支持?】
在IP路由的数据中心网络上,RDMA使用RoCEv2协议进行部署,RoCEv2依赖PFC来实现无损网络(drop-free network)。
比较尴尬的是,RDMA对丢包率的要求极高。0.1%的丢包率,将导致RDMA吞吐率急剧下降。2%的丢包率,将使得RDMA的吞吐率下降为0
讨论了RDMA在容损网络和无损网络两种思路的发展历程,还举了近期的例子来说明,如
基于容损网络的SIGCOMM2018:Revisiting Network Support for RDMA :
SIGCOMM2018会议上,提出了IRN(Improved RoCE NIC)算法。该设计仍然保留“选择性重传”(允许丢包重传,所以是容损) 这一设计思路,作者认为iWarp的思路大方向正确,但是TCP协议对于智能网卡太过复杂,需要简化。截至今年(2021年),该设计仍处于实验室阶段,没有经过任何生产环境的考验。
基于无损网络的SIGCOMM2019:High Precision Congestion Control(HPCC)
最开始RDMA技术是基于InfiniBand的,数据包丢失在此类群集中很少见,因此RDMA Infiniband传输层(在NIC上实现)的重传机制很简陋,即:go-back-N重传,但是现在RDMA的使用更广泛,在其他网络中(如基于以太网的RoCE网络),丢包的概率大于Infiniband集群,一旦丢包,使用RDMA的go-back-N重传机制效率非常低,会大大降低RDMA的传输效率,所以要想发挥出RDMA真正的性能,势必要为RDMA搭建一套不丢包的无损网络环境
早期的经验表明,RoCE NIC只有在不丢包网络上运行时才能取得良好的端到端性能(因为RoCE使用的是go-back-N重传,丢包后果很严重),因此运营商转向以太网优先级流控(PFC)机制
limitations of PFC
【PFC的限制】
PFC(Priority-based Flow Control)是一种粗粒度的机制。其PAUSE机制进行流控的粒度是端口(或端口加优先级)的级别,而没有细化到flow的级别。因此PFC会导致head-of-line blocking (victim flow), unfairness和congestion-spreading等问题。
我的理解是:PFC的PAUSE机制会ban掉一整条ingress(或该ingress中的某个优先级)上的所有flow
那么什么是基于flow的呢?flow可以理解成ip五元组:<协议类型、源IP地址、目的IP地址、源端口号、目的端口号>,对于TCP来讲就是一条TCP链接。但是一条连接中也可以有多条flow
所以DCQCN、DCTCP乃至TCP这种端到端的CC都可以理解成基于flow的(?)
- ingress和egress:
- Ingress - This is used to describe the port where a frame enters the device.
- Egress - This is used to describe the port that frames will use when leaving the device.
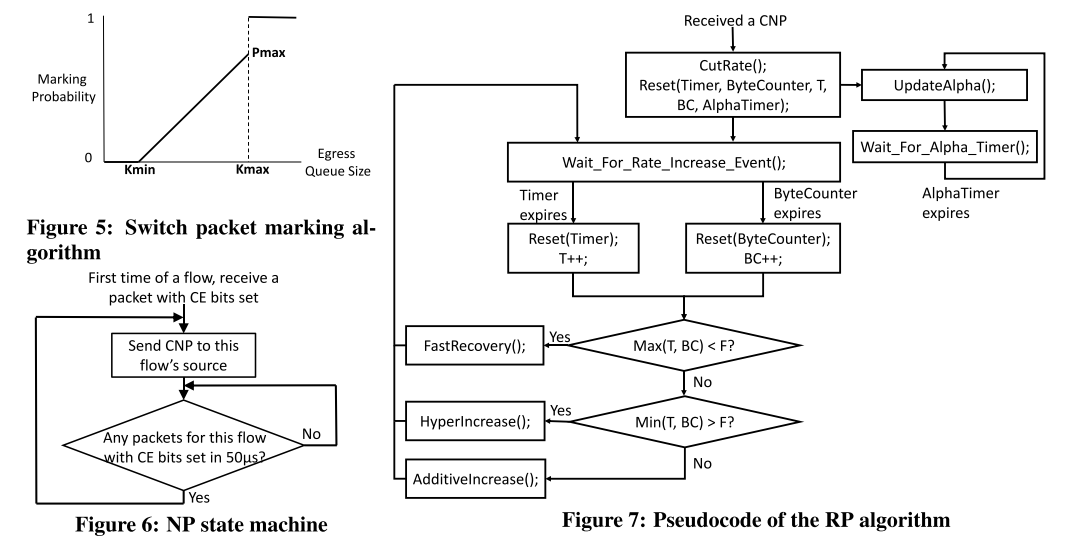
Algorithm
分为三部分:
The DCQCN algorithm consists of the sender (reaction point (RP)), the switch (congestion point (CP)), and the receiver, (notification point (NP)).
CP Algorithm: 与DCTCP类似,在egress queue中设置threshold并打上ECN标记
NP Algorithm: 按照一定的规则,生成Congestion Notification Packets (CNP)提醒拥塞发生
RP Algorithm: 按照状态机,对CNP做出反应,控制发送速率
note
【注释】
PFC(Priority based Flow Control)是在交换机入口(ingress port)发起的拥塞管理机制。在通常无拥塞情况下,交换机的入口 buffer 不需要存储数据。当交换机出口(egress port)的 buffer 达到一定的阈值时,交换机的入口 buffer 开始积累,当入口 buffer 达到我们设定的阈值时,交换机入口开始主动的迫使它的上级端口降速。
ECN(Explicit Congestion Notification) 是在交换机出口(egress port)发起的拥塞控制机制。当交换机的出口 buffer 达到我们设定的阈值时,交换机会改变数据包头中的 ECN 位来给数据打上 ECN 标签
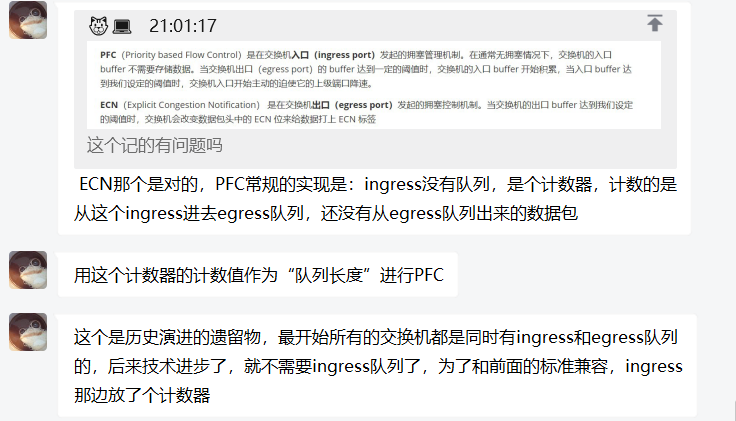
从充分发挥网络高性能转发的角度,我们一般建议==通过调整ECN和PFC的buffer水线,让ECN快于PFC触发==,即网络还是持续全速进行数据转发,让服务器主动降低发包速率。如果还不能解决问题,再通过PFC让上游交换机暂停报文发送,虽然整网吞吐性能降低,但是不会产生丢包。
TIMELY: RTT-based Congestion Control for the Datacenter
【==TIMELY好像没提怎么应对delayed-ACK?==】
We also measure the minimum RTT sample in every round, as prior work has found it to be a robust descriptor untainted by delayed ACKs and send/receive offload schemes.
Abstract
simple packet delay, measured as round-trip times at hosts, is an effective congestion signal without the need for switch feedback.
逐包延迟是有效的拥塞信号,同时也不需要交换机的反馈
these RTTs are sufficient to estimate switch queueing
RTT足以用来估计交换机的队列
TIMELY is the first delay-based congestion control protocol for use in the datacenter, and it achieves its results despite having an order of magnitude fewer RTT signals (due to NIC
offload) than earlier delay-based schemes such as Vegas.TIMELY是DC中的首个delay-based的CC协议,它用比早期的delay-based的CC(如Vegas)少一个数量级的RTT信号(受限于NIC offload)实现了其结果。
Background
使用ECN控制queue occupancy的方法的不足:
一些场景中,ECN所表示的queue occupancy队列占用并不能直观反映排队延迟
如一个队列中的数据包有多种优先级,尽管队列长度没有超过threshold,低优先级的流量同样有可能经历巨大的delay。这个时候delay反映了occupancy没能反映的拥塞状况。
Multiple queues with different priorities share the same output link, but the ECN mark only provides information about those with occupancy exceeding a threshold. Low priority traffic can experience large queueing delays without necessarily building up a large queue. In such circumstances, queueing delay reflects the state of congestion in the network which is not reflected by queue occupancy of low priority traffic.
ECN只能描述单个交换机中的拥塞
而RTT信息累积了端到端的拥塞信息,甚至包括了NIC中的拥塞。
In a highly utilized network, congestion occurs at multiple switches, and ECN signals cannot differentiate among them.
The RTT accumulates information about the end-to-end path. It includes the NIC, which may also become congested but is ignored by most schemes.
RTTs甚至在FCoE中也可以适用
RTTs work even for the lossless network fabrics commonly used to support FCoE.
FCoE 协议要求底层的物理传输是无损失的;FCoE 不使用 TCP/IP 协议,因此 FCoE 数据传输不能使用 IP 网络,也就无法使用DCTCP这样的CC。
NIC的发展支持
recent NIC advances do allow data-center RTTs to be measured with sufficient precision.
recent NICs can accurately record the time of packet transmission and reception without being affected by software-incurred delays.
These methods must be used with care lest they overly tax the NIC.
RTT作为拥塞信号比ECN更有效。
RTT is a rapid, multi-bit signal.
As a binary quantity, ECN marks convey a single bit of information, while RTT measurements convey multiple bits and capture the full extent of end to end queueing delay aggregated across multiple switches rather than the presence of queueing exceeding a simple fixed threshold at any one ofN switches.
- Figure 2 shows the CDF of RTTs as measured at the end system compared to the queue occupancy measured directly at the switch and shown in units of time computed for a 10 Gbps link. The two CDFs match extremely well.
- Both the scatter and box plots in Figure 3 show only a weak correlation between the fraction of ECN marks and RTTs.
RTTs的不足
Limitations of RTTs.
- *RTT measurements lump queueing in both directions along the network path. This may confuse reverse path congestion experienced by ACKs with forward path congestion experienced by data packets.*——send ACKs with higher priority
- changing network paths have disparate delays——all paths have small propagation delays in datacenters
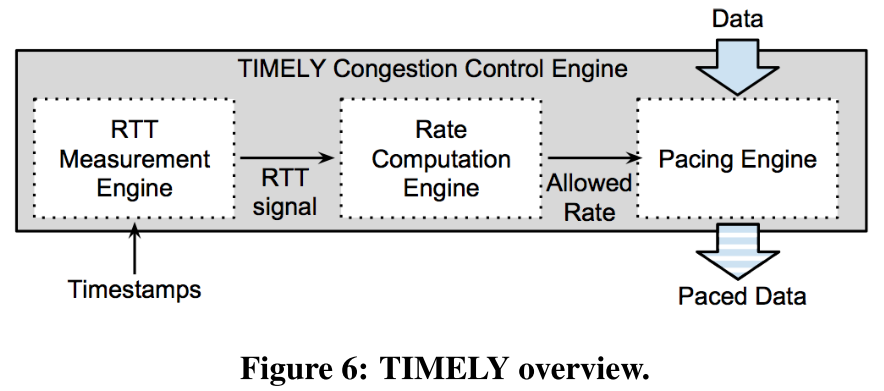
TIMELY FRAMEWORK
三部分:
- RTT measurement to monitor the network for congestion;
- a computation engine that converts RTT signals into target sending rates; and
- a control engine that inserts delays between segments to achieve the target rate.
如下图:
RTT Measurement Engine
==A completion event is generated upon receiving an ACK for a segment of data and includes the ACK receive time. The time from when the first packet is sent ($$t_{send}$$) until the ACK is received ($$t_{completion}$$) is defined as the completion time. Unlike TCP, there is one RTT for the set of packets rather than one RTT per 1-2 packets.==
the timeline of a message: a segment consisting of multiple packets is sent as a single burst and then ACKed as a unit by the receiver.
There are several delay components:
- (传输延迟)the serialization delay to transmit all packets in the segment, typically up to 64 KB;
(deterministic function(确定性函数) of the segment size and the line rate of the NIC)
2) (传播延迟)the round-trip wire delay for the segment and its ACK to propagate across the datacenter; the minimum RTT and fixed for a given flow
3) the turnaround time at the receiver to generate the ACK; and sufficiently close to zero in our setting with NIC-based ACKs that we can ignore it
4) (排队延迟)the queuing delay at switches experienced in both directions. causes variation in the RTT, our focus for detecting congestion
We define the RTT to be the propagation and queueing delay components only.
示意图如下图:
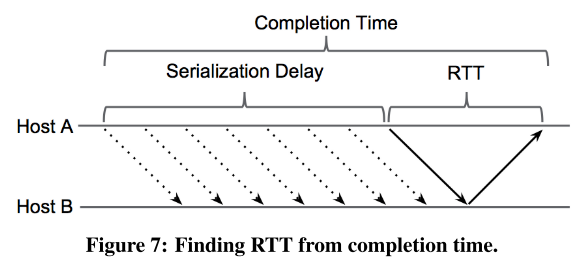
TIMELY running on Host A computes RTT as:
$$
RTT = t_{completion} - t_{send} - \frac{seg.size}{NIC\ line\ rate}
$$
The time from when the first packet is sent (tsend) until the ACK is received (tcompletion) is defined as the completion time.
Rate Computation Engine
The rate computation engine runs the congestion control algorithm upon each completion event, and outputs an updated target rate for the flow.
Rate Control Engine
TIMELY CONGESTION CONTROL
Metrics and Setting
tail (99th percentile) RTT and aggregate throughput: they determine how quickly we complete short and long RPCs (assuming some fairness)
When there is a conflict between throughput and packet RTT, we prefer to keep RTT low at the cost of sacrificing a small amount of bandwidth.
fairness and loss: We report both as a check rather than study them in detail.
Finally, we prefer a stable design over higher average, but oscillating rates for the sake of predictable performance.
最后,为了性能可以预测,我们更喜欢一个稳定的设计,而不是平均水平更高的同时振荡率更好。
Delay Gradient Approach
先前的Delay-based CC,如TCP Vegas及受其启发的FAST TCP, Compound TCP的共同特点:
These interpret RTT increase above a baseline as indicative of congestion: they reduce the sending rate / if delay is further increased / to try and maintain / buffer occupancy at the bottleneck queue around some predefined threshold.
此前的Delay-based CC都是预先设定队列长度(以delay为单位)的阈值,来控制队列长度。
先前方法的缺陷:
- it is not possible to control the queue size when it is shorter in time than the control loop delay
- The most any algorithm can do in these circumstances is to control the distribution of the queue occupancy. Even if controlling the queue size were possible, choosing a threshold for a datacenter network in which multiple queues can be a bottleneck is a notoriously hard tuning problem.
TIMELY的方法:
TIMELY’s congestion controller achieves low latencies by reacting to the delay gradient or derivative of the queuing with respect to time, instead of trying to maintain a standing queue.
By using the gradient, we can react to queue growth without waiting for a standing queue to form – a strategy that helps us achieve low latencies.
the delay gradient measured through RTT signals acts as an indicator for the rate mismatch at the bottleneck
TIMELY strives to match the aggregate incoming rate y(t) to the drain rate, C, and so adapts its per-connection rate, R(t), in proportion to the measured error of
$$
\frac{y(t)-C}{C} = \frac{dq(t)}{dt} = \frac{d(RTT)}{dt}
$$queuing delay through the bottleneck queue: $$q(t)$$
The Main Algorithm
根据新RTT的值,来adjust sending rate
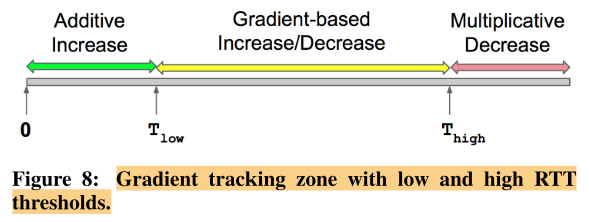
Connections sending at a higher rate observe a stronger decrease in their rate, while the increase in rate remains same for all connections.
Need for RTT low threshold $$T_{low}$$
large segments (that can be as large as 64 KB) lead to packet bursts, which result in transient queues in the network and hence RTT spikes when there is an occasional collision
$$T_{low}$$ is a (nonlinear) increasing function of the segment size used in the network, since larger messages cause more bursty queue occupancy.
Need for RTT low threshold $$T_{high}$$
in theory, it is possible for the gradient to stay at zero while the queue remains at a high, fixed level
To remove this concern, Thigh serves as an upper bound on the tolerable end-to-end network queue delay, i.e., the tail latency.
Note that we use the instantaneous rather than smoothed RTT.
Our finding is inline with [27] which shows through a control theoretic analysis that the averaged queue length is a failing of RED AQM
Hyperactive increase (HAI) for faster convergence.
Gradient versus Queue Size
Gradient versus Queue Size
If we set the same value for $$T_{low}$$and $$T_{high}$$, then TIMELY congestion control reduces to a queue size based approach (similar to TCP FAST algorithm; FAST in turn is a scaled, improved version of Vegas).
We see that the queue size approach can maintain either low latency or high throughput, but finds it hard to do both.
the connection rates oscillate more in the queue-size approach, as it drives the RTT up and down towards the target queue size.
The main take-away is that $$T_{low}$$and $$T_{high}$$ thresholds effectively bring the delay within a target range and play a role similar to the target queue occupancy in many AQM schemes.
IMPLEMENTATION
Transport Interface
TIMELY is concerned with the congestion control portion of the transport protocol; it is not concerned with reliability or the higher-level interface the transport exposes to applications. This allows the interface to the rest of the transport to be simple: message send and receive.
Using NIC Completions for RTT Measurement
NIC records: absolute timestamp of when the multi-packet operation finishes
userspace software records: the operation was posted to the NIC
(reason: We consider any NIC queuing occurring to be part of the RTT signal.)
我们需要将网卡的排队时间也考虑在内,NIC记录的时间戳不包含这个时间,software记录的时间戳包含;但是由于NIC比较准确,想使用NIC的时间,所以需要将software映射到NIC timestamps,这里使用线性映射
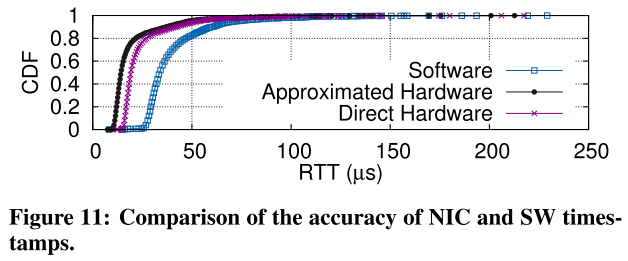
This requires a scheme to map host clock to NIC clock, as well as calibration. A simple linear mapping is sufficient.
RDMA rate control.
RDMA Writes: TIMELY on the sender directly controls the segment pacing rate.
RDMA Reads: the receiver issues read requests, in response to which the remote host performs a DMA of the data segments. (pacing the read requests)
Application limited behavior.
Applications do not always have enough data to transmit for their flows to reach the target rate.
When this happens, we do not want to inadvertently increase the target rate without bound because the network appears to be uncongested. 在app向下发数据的速率小于target rate的时候,网络看起来是没有拥塞的,但此时并不能表明网络无拥塞,所以不能盲目提高发送速率。
To prevent this problem, we let the target rate increase only if the application is sending at more than 80% of the target rate, and we also cap the maximum target rate at 10 Gbps.
Rate update frequency.
Swift: Delay is Simple and Effective for Congestion Control in the Datacenter
Swift targets an end-to-end delay by using AIMD control, with pacing under extreme congestion.
Delay is easy to decompose into fabric and host components to separate concerns.
细化了delay的组成,强调了endpoints上产生的delay
- 本文链接:https://wan-nan.github.io/2023/07/08/%E6%96%87%E7%8C%AE%E9%98%85%E8%AF%BB/
- 版权声明:本博客所有文章除特别声明外,均默认采用 许可协议。